[자바 ORM 표준 JPA 프로그래밍] 10장. 객체지향 쿼리 언어
by Jo
10장. 객체지향 쿼리 언어
10.1 객체지향 쿼리 소개
- JPQL 특징
- DB 테이블이 아닌 엔티티 객체를 대상으로 검색하는 객체지향 쿼리
- SQL을 추상화하여 특정 DB SQL에 의존 X
- JPA에서 공식 지원하는 기능
- JPQL(Java Persistence Query Langauge)
- Creiteria 쿼리: JPA 작성 도와주는 API, 빌더 클래스 모음
- 네이티브 SQL: JPA에서 JPQL 대신 직접 SQL 사용 도움
- JPA에서 공식 지원하는 건 아니지만 유용한 기능
- QueryDSL: Criteria 쿼리처럼 JPQL 작성 편의 도와주는 빌더 클래스 모음. 비표준 오픈소스 프레임워크임
- JDBC 직접 사용, MyBatis 같은 SQL 매퍼 프레임워크 사용: 필요하면 직접 JDBC 사용 가능k
JPQL
- 객체지향 쿼리 언어
- 테이블 대상이 아닌 엔티티 객체를 대상으로 쿼리
- SQL을 추상화하여 특정 DB SQL에 의존하지 않음
- SQL로 변환되어 실행
- JPQL API는 대부분 메소드 체인 방식으로 설계되어있어서 연속으로 작성 가능
샘플 모델 UML
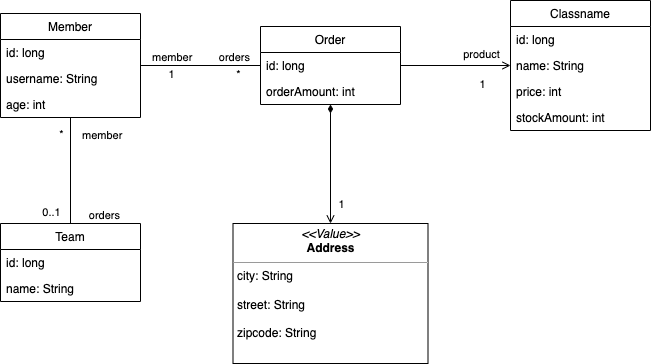
샘플 모델 ERD
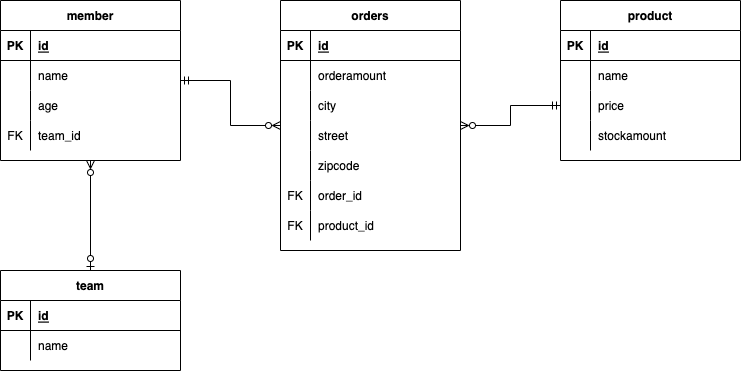
10.2.1 기본 문법과 쿼리 API
- JPQL도 SQL과 비슷하게 SELECT, UPDATE, DELETE 문 사용 가능
- 저장시에는
EntityManager::persist()사용하면 되서 INSERT 는 없음
코드
select_문 ::=
select_절
from_절
[where_절]
[groupby_절]
[having_절]
[orderby_절]
update_문 ::= update_절 [where_절]
delete_문 ::= delete_절 [where_절]
SELECT 문
SELECT m FROM Member AS m WHERE m.username = 'Hello'
- 대소문자 구분
- 엔티티, 속성은 대소문자를 구분 O
- SELECT, FROM, AS 같은 JPQL 키워드는 대소문자 구분 X
- 엔티티 이름
- 디폴드 값은 클래스 명
@Entity(name="")으로 지정 가능
- 별칭은 필수
Member As m처럼 JPQL에선 alias 지정 필수임- AS는 생략 가능
TypeQuery, Query
- 작성한 JPQL 실행 위해 쿼리 객체 필요
- 반환할 타입 명확하게 지정 가능하면 TypeQuery 객체 사용
- 반환 타입 명확하게 지정 불가능하면 Query 객체 사용
코드
public void useTypeQuery(EntityManager em) {
TypeQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
List<Member> resultList = query.getResultList();
for (Member member: resultList) {
System.out.println("member = " + member);
}
}
...
public void useQuery(EntityManager em) {
Query query = em.createQuery("SELECT m.username, m.age FROM Member m");
List resultList = query.getResultList();
for (Object o: resulstList) {
Object[] result = (Object[]) o; // 결과가 둘 이상이면 Object[] 반환
System.out.println("username = " + result[0]);
System.out.println("age = " + result[1]);
}
}
결과 조회
- 아래 메소드들 호출시 실제 쿼리 실행하여 DB 조회함
query.getResultList(): 결과를 반환. 없으면 빈 컬렉션 반환query.getSingleResult(): 결과가 정확히 하나일 때 사용- 결과 없으면
javax.persistence.NoResultException발생 - 결과가 1개보다 많으면
javax.persistence.NoUniqueResultException발생
- 결과 없으면
10.2.2 파라미터 바인딩
- JPQL은 이름 기준 파라미터 바인딩 지원
- JDBC는 위치 기준 파라미터 바인딩만 지원
- 파라미터 바인딩을 사용하지 않고 직접 문자 더해 만들어 넣으면 SQL 인젝션 공격 당할 수 있음
- 또한 파라미터 바인딩 방식 쓰면 파리미터 값 달라도 같은 쿼리로 인식해 JPQL을 SQL로 파싱한 결과를 재사용 할 수 있음
이름 기준 파라미터
- 파라미터를 이름으로 구분하는 방법
- 이름 기준 파라미터는 앞에 : 붙임
코드
Strign usernameParam = "User1";
List<Member> resulstList = em
.createQuery("SELECT m FROM Member m WHERE m.username = :username", Member.class) // :username이 이름 기준 파라미터 정의
.setParameter("username", usernameParam); // setParameter로 파라미터 바인딩
.getResultList();
위치 기준 파라미터
- 파라미터를 위치 기준으로 구분하는 방법
- ? 다음에 위치 값 주면 됨
- 위치 값은 1부터 시작
코드
List<Member> members = em
.createQuery("SELECT m FROM Member m WHERE m.username = ?1", Member.class)
.setParameter(1, usernameParam)
.getResultList();
10.2.3 프로젝션
- SELECT 절에 조회할 대상을 지정하는 것 = projection
SELECT {프로젝션 대상} FROM으로 대상 선택- 대상으로는 엔티티, 임베디드 타입, 스칼라 타입이 있음
엔티티 프로젝션
SELECT m FROM Member m // Member
SELECT m.team FROM Member m // Team
- 위 예시처럼 엔티티를 프로젝션 대상으로 사용해서 원하는 객체를 바로 조회
- 이렇게 조회한 엔티티는 영속성 컨텍스트에서 관리됨
임베디드 타입 프로젝션
List<Address> address = em
.createQuery("SELECT o.address FROM Order o", Address.class)
.getResultList();
- 임베디드 타입은 조회의 시작점이 될 수 없음
- 위 예시처럼 엔티티를 통해서 조회해야 함
- 임베디드 타입은 값 타입이기 때문에 영속성 컨텍스트에서 관리 X
스칼라 타입 프로젝션
List<String> usernames = em
.createQuery("SELECT username FROM Member m", String.class)
.getResultList();
- 숫자, 문자, 날짜와 같은 기본 데이터 타입들
- AVG, SUM 같은 통계 쿼리도 주로 스칼라 타입으로 조회함
여러 값 조회
코드
List<Object[]> resultList = em
.createQuery("SELECT o.member, o.product, o.orderAmount FROM Order o")
.getResultList();
for (Object[] row: resultList) {
Member member = (Member) row[0]; // 엔티티
Product product = (Product) row[1]; // 엔티티
int orderAmount = (Integer) row[2]; // 스칼라
}
- 프로젝션에 여러 값 선택시 TypeQuery 대신 Query 써야 함
- 엔티티 타입도 여러 값 함께 조회 가능하며, 이 엔티티들도 영속성 컨텍스트로 관리 됨
NEW 명령어
코드
TypeQuery<UserDTO> query = em.createQuery("SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m", UserDTO.class);
List<UserDTO> resultList = query.getResultList();
- SELECT 다음에 NEW 명령어 사용하여 반환받을 클래스 지정하고 해당 클래스의 생성자에 JPQL 조회 결과 넘겨줄 수 있음
- 이렇게 하면 TypeQuery 사용해서 바로 변환된 객체로 리턴받을 수 있음
- NEW 명령어 사용시 주의점
- 패키지 명을 포함한 전체 클래스 명 써야함
- 순서와 타입이 일치하는 생성자 있어야 함
10.2.4 페이징 API
- JPA는 페이징을 아래 두 API로 추상화
setFirstResult(int startPosition): 조회 시작 위치(0부터 시작)setMaxResults(int maxResult): 조회할 데이터 수
- DB dialect에 따라 사용중인 DB에 알맞은 SQL로 자동 변환되어 쿼리 수행됨
- 최적화 더 하려면 Native SQL 사용해야 함
코드
List<Member> resultList = em
.createQuery("SELECT m FROM Member m ORDER BY m.username DESC", Member.class)
.setFirstResult(10); // 조회 시작 위치는 11번째(0번째가 시작이므로)
.setMaxResults(20); // 조회할 데이터 수는 20개
.getResultList(); // 결과적으로 11~30번 데이터가 조회됨
10.2.5 집합과 정렬
- 집합은 집합함수와 함께 통계 정보 구할 때 사용
집합 함수
| 함수 | 설명 | 리턴 타입 |
|---|---|---|
| COUNT | 결과 갯수를 구함 | Long |
| MAX, MIN | 최대, 최솟값 구함. 문자, 숫자, 날짜 등에 사용 | |
| AVG | 평균값 구함. 숫자 타입만 사용 가능 | Double |
| SUM | 합을 구함. 숫자 타입만 사용 가능 | 정수합: Long 소수합: Double BigInteger합: BigInteger BigDecimal합: BigDecimal |
- 집합 함수 사용시 참고사항
- null 값은 무시하므로 통계에 잡히지 않음(DISTINCT 정의되어 있어도 무시됨)
- 값 없는데 SUM, AVG, MAX, MIN 사용시 null 값이 됨
- COUNT는 0 됨
- DISTINCT 를 집합 함수 안에 사용해서 중복값 제거 후 집합 구할 수 있음
- ex)
SELECT COUNT(DISTINCT m.age) FROM Member m
- ex)
- DISTINCT 를 COUNT 에서 사용할 때 임베디드 타입은 지원 X
GROUP BY, HAVING
groupby_절 ::= GROUP BY {단일값 경로 | alias}+
having_절 ::= HAVING 조건식
- GROUP BY는 통계 데이터 구할 때 특정 그룹끼리 묶어줌
// 팀 이름을 기준으로 그룹화하여 통계 데이터 구하기
SELECT t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
FROM Member m
LEFT JOIN m.team t
GROUP BY t.name
- HAVING 은 GROUP BY 와 함께 사용하며 그룹화된 통계 데이터를 기준으로 필터링 함
// 그룹별 통계 데이터 중 평균 나이가 10살 이상인 그룹 조회
// 팀 이름을 기준으로 그룹화하여 통계 데이터 구하기
SELECT t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
FROM Member m
LEFT JOIN m.team t
GROUP BY t.name
HAVING AGV(m.age) >= 10
정렬(ORDER BY)
orderby_절 ::= ORDER BY {상태필드 경로 | 결과 변수 [ASC | DESC]}+
- 결과 정렬시 사용
- ASC: 오름차순 (default)
- DESC: 내림차순
- 상태필드는
t.name과 같이 객체의 상태를 나타내는 필드를 말함 - 결과 변수는 SELECT 절에 나타나는 값을 말함
- 아래 예제의 경우 t.name, cnt 가 결과 변수이고, 그중 cnt를 기준으로 정렬시킴
SELECT t.name, COUNT(m.age) as cnt
FROM Member m
LEFT JOIN m.team t
GROUP BY t.name
ORDER BY cnt
10.2.6 JPQL 조인
- SQL 조인과 기능 동일, 문법만 약간 상이함
내부 조인
코드
String teamName = "teamA";
List<Member> members = em
.createQuery("SELECT m FROM Member m INNER JOIN m.team t WHERE t.name = :teamName", Member.class)
.setParameter("teamName", teamName)
.getResultList();
- INNSER JOIN 사용, INNER 는 생략 가능
- JPQL 은 연관 필드를 사용하여 조인함
- 연관 필드는 다른 엔티티와 연관관계를 가지기 위해 사용하는 필드
- 위 예제의 경우
m.team이 연관필드임
외부 조인
코드
SELECT m
FROM Member m
LEFT OUTER JOIN m.team t
- OUTER 는 생략 가능
- 마찬가지로 연관필드 가지고 조인
컬렉션 조인
- 1:1, N:N 관계처럼 컬렉션 사용하는 곳에 조인하는 것
- [Member -> Team] 조인은 N:1 조인이면서 단일 값 연관 필드(m.team) 사용
- [Team -> Member]는 1:N 조인이면서 컬렉션 값 연관 필드(m.members) 사용
SELECT t, m
FROM Team t
LEFT JOIN t.members m // Team 과 Team 이 보유한 Member 목록을 컬렉션 값 연관 필드로 외부 조인한 것
세타 조인
- WHERE 절을 사용해서 세타 조인 가능
- 내부 조인만 지원함
- 세타 조인을 사용해 전혀 관계없는 엔티티도 조인 가능
코드
SELECT count(m)
FROM Member m,
Team t
WHERE m.username = t.name // WHERE 절에서 전혀 관계 없는 Member.username 과 Team.name 을 조인함
JOIN ON 절(JPA 2.1 이상 지원)
- JPA 2.1 부터 조인시 ON 절을 지원
- ON 절 사용하면 조인 대상 필터링 후 조인 가능
- 내부 조인의 ON절은 WHERE 절 사용하는 거랑 결과 같으므로 보통 외부 조인에서만 사용함
코드
SELECT m, t
FROM Member m
LEFT JOIN m.team t ON t.name = 'A' // t.name = 'A' 로 조인 시점에 조인 대상을 필터링
10.2.7 페치 조인
- JPQL에서 성능 최적화를 위해 제공
- 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능
- JOIN FETCH 명령어로 사용 가능
- 페치 조인에서는 alias 못씀
페치 조인 ::= [ LEFT [OUTER] | INNER ] JOIN FETCH 조인경로
엔티티 페치 조인
코드
List<Member> members = em
.createQuery("SELECT m FROM Member m JOIN FETCH m.team")
.getResultList();
for (Member member: members) {
// 페치 조인으로 Member 조회시 Team 도 함께 조회되어 지연 로딩 X
System.out.println("username = " + member.getUsername() + ", " + "teamname = " + member.getTeam().name());
}
- 위 예제의 경우 Member(m) 과 Team(m.team) 을 함께 조회함
SELECT m으로 Member 만 선택했지만 실제로 실행된 SQL에서는SELECT m.*, t.*로 member와 연관된 team 도 함께 조회함- ∴ 지연 로딩 설정 해놨어도 Member 조회시 Team 도 같이 조회되어 지연 로딩 발생 안함
컬렉션 페치 조인
코드
List<Team> teams = em
.createQuery("SELECT t FROM Team t JOIN FETCH t.members WHERE t.name = 'teamA'", Team.class)
.getResultList();
for (Team team: teams) {
System.out.println("teamname = " + team.getName() + ", team = " + team);
for (Member member: team.getMembers()) {
// 페치 조인으로 Team 조회시 Member 도 함께 조회되어 지연 로딩 X
System.out.println("->username = " + member.getUsername() + ", member = " + member);
}
}
SELECT t로 Team 만 선택했지만 실제로 실행되는건SELECT t.*, m.*로 team 과 연관된 member도 함께 조회함- 만약 ‘teamA’에 속한 member가 여러명이라면
getResultList()의 결과로 member 수만큼의 team이 반환됨- 반환되는 team은 모두 동일한(identity) 객체임
페치 조인과 DISTINCT
- JPQL의 DITSINCT는 SQL에 DISTINCT 명령어 추가 및 에플리케이션에서 한번 더 중복 제거
- 앞서 컬렉션 페치 조인 같은 경우 그냥 조회하면 여러 member 속한 team은 그 수만큼 반환
- DISTINCT 붙여서 조회해도 원래 sql이라면 각 row의 member 데이터가 달라서 중복 제거가 안됨
- 하지만 JPQL에서의 DISTINCT는 에플리케이션에서 한번 더 중복 제거해주므로 중복된 team entity 제거됨
페치 조인과 일반 조인의 차이
- 일반 조인
- JPQL은 결과 반환시 연관관계까지 고려 X, SELECT 절에 지정한 엔티티만 조회
- ∴ 지연 로딩 설정시엔 프록시를, 즉시 로딩 설정시엔 연관된 엔티티 조회를 위해 쿼리를 한번 더 실행함
- 페치 조인
- 연관된 엔티티도 함께 조회
- ∴ 연관된 엔티티 위해 쿼리 한번더 실행하지 않고 한번에 해결
페치 조인의 특징과 한계
- 특징
- 페치 조인 사용시 쿼리 한번으로 연관된 엔티티 함께 조회할 수 있어 호출 회수 줄이고 성능 최적화 가능
- 페치 조인은 글로벌 로딩 전략(엔티티에 직접 작용하는 로딩 전략, ex.
@OneToMany(fetch = FetchType.LAZY))보다 우선함- ∴ 글로벌 로딩 전략을 지연 로딩으로 해놔도 JPQL 에서 페치 조인 쓰면 페치 조인 적용해서 한번에 조회함
- 최적화를 위해 글로벌 로딩 전략으로 즉시 로딩 설정시 일부는 효율적일 수 있지만 전체적으로는 안쓰는거 자주 로딩해서 악영향 올 수 있음
- ∴ 글로벌 로딩 전략은 지연 로딩, 최적화 필요한 곳에 페치 조인 적용하는게 좋음
- 객체 그래프 유지할 때 사용하면 유용ㅍ
- 여러 테이블 조인해서 엔티티 본 모양이 아닌 다른 결과 내어야 하면 그냥 필요한 필드들만 각각 조회해서 DTO로 반환하는게 나을수도 있음
- 한계
- 페치 조인 대상에는 alias 불가
- ∴ SELECT, WHERE, 서브쿼리에 페치 조인 대상 사용 불가
- 하이버네이트등 일부 구현체는 alias 지원하나 잘못 쓰면 연관된 데이터 수 달라져 데이터 무결성 깨질 수 있으므로 조심해야함
- 2차 캐시랑 같이 쓸 때 특히 조심
- 둘 이상의 컬렉션 페치 불가
- 구현체의 따라 가능하나 컬렉션 * 컬렉션의 카테시안 곱 만들어지므로 주의 필요
- 하이버네이트는 예외 발생
- 컬렉션 페치 조인시 페이징 API(setFirstResult, setMaxResults) 사용 불가
- 컬렉션(1:N)이 아닌 단일 값 연관 필드(1:1, N:1) 들은 페치 조인 써도 페이징 API 못씀
- 하이버네이트에서는 경고 로그 남기고 메모리에서 페이징 처리함 => 성능 이슈 및 메모리 초과 예외 발생 가능
- 페치 조인 대상에는 alias 불가
10.2.8 경로 표현식 (Path Expression)
SELECT m.username
FROM Member m
join m.team t
join m.orders o
WHERE t.name = 'teamA'
- .을 찍어 객체 그래프를 탐색하는 것
- 위 예제에서
m.username,m.team,m.orders,t.name이 모두 경로 표현식 사용 예
경로 표현식의 용어 정리
- 상태 필드 state field: 단순히 값 저장하기 위한 필드(필드 or 프로퍼티)
m.username,t.name
- 연관 필드 association field: 연관관계 위한 필드, 임베디드 타입 포함(필드 or 프로퍼티)
- 단일 값 연관 필드:
@ManyToOne,@OneToOne, 대상이 엔티티m.team
- 컬렉션 값 연관 필드:
@OneToMany,@ManyToMany, 대상이 컬렉션m.orders
- 단일 값 연관 필드:
코드
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "name")
private String username; // state field
private Integer age; // stae field
@ManyToOne(...)
private Team team; // association field
@OneToMany(...)
private List<Order> orders; // association field
}
경로 표현식과 특징
- 상태 필드 경로: 경로 탐색의 끝. 더이상 탐색 X
- 단일 값 연관 경로: 묵시적으로 내부 조인 일어남. 계속 탐색 O
- 컬렉션 값 연관 경로: 묵시적으로 내부 조인 일어남. 더이상 탐색 X 지만 FROM 절에서 조인 통해 alias 얻으면 alias 로 탐색 O
// 상태 필드 경로 탐색
// JPQL
SELECT m.username, m.age FROM Member m
// 실행 쿼리
SELECT m.name, m.age
FROM Member m
...
// 단일 값 연관 경로 탐색
// JPQL
SELECT o.member FROM Order o
// 실행 쿼리
SELECT m.*
FROM Orders o
INNER JOIN Member m on o.member_id = m.id // 묵시적 조인(내부 조인). 외부 조인은 JPQL에 JOIN 키워드 명시적으로 사용해야 함
...
// 컬렉션 값 연관 경로 탐색
// JPQL
SELECT t.members from Team t // 성공
SELECT t.members.username FROM Team t // 실패
// t.members 처럼 컬렉션 까지는 경로 탐색 가능하지만,
// t.members.username 처럼 컬렉션에서 경로 탐색 시작은 불가능
// 계속 하려면 아래처럼 조인을 사용해서 새로운 alias 획득해야 함
SELECT m.username FROM Team t JOIN t.members m
// 컬렉션에서는 크기 구할 수 있느 size 기능 사용 가능
// COUNT 함수 쓰는 쿼리로 알아서 변환됨
SELECT t.members.size FROM Team t
경로 탐색을 사용한 묵시적 조인 시 주의사항
- 항상 내부 조인임
- 컬렉션은 경로 탐색의 끝
- 컬렉션에서 경로 탐색 하려면 명시적 조인으로 alias 획득 필요
- 주로 SELECT, WHERE 절에서 사용하지만 묵시적 조인으로 인해 FROM 절에 영향 줌
- 묵시적 조인은 조인 발생 현환 파악 어려우므로 명시적 조인 쓰는게 좋음
10.2.9 서브 쿼리
- WHERE, HAVING 절에만 사용 가능, SELECT, FROM 절에선 못 씀
- 하이버네이트 HQL은 SELECT 절 서브쿼리 까지는 허용
// 나이가 평균보다 많은 회원 조회
SELECT m FROM Member m
WHERE m.age > (SELECT AVG(m2.age) FROM Member m2)
// 한 건이라도 주문한 고객 조회
SELECT m FROM Member m
WHERE (SELECT COUNT(o) FROM Order o WHERE m = o.member) > 0
// 한 건이라도 주문한 고객 조회 (컬렉션 크기 값 구할 수 있는 size 기능 활용, 실행 쿼리는 위에거랑 동일)
SELECT m FROM Member m
WEHRE m.orders.size > 0
서브 쿼리 함수
- EXISTS
- [NOT] EXISTS (subquery)
- subquery에 결과 존재하면 참, NOT 붙으면 반대
- ALL, ANY, SOME
-
{ALL ANY SOME} (subquery) - 비교 연산자와 같이 사용
-
{= > >= < <= <>}
-
- ALL: 조건 모두 만족시 참
- ANY, SOME: 조건 하나라도 만족하면 참
-
- IN
- [NOT] IN (subquery)
- subquery 결과 중 하나라도 같은 것 있으면 참
10.2.10 조건식
타입 표현
| 종류 | 설명 | 예제 |
|---|---|---|
| 문자 | 작은 따옴표 사이에 표현 작은 따옴표 표현하려면 연속 두개 사용(‘’) |
‘HELLO’ ‘She’’s’ |
| 숫자 | L(Long) D(Double) F(Float) |
10L 10D 10F |
| 날짜 | DATE {d ‘yyyy-mm-dd’} TIME {t ‘hh-mm-ss’} DATETIME {ts ‘yyyy-mm-dd hh:mm:ss.f’} |
{d ‘2021-03-03’} {t ‘11-11-11’} {ts ‘2021-03-03 11-11-11.111’} m.createDate = {d ‘ 2021-03-03’} |
| Boolean | True, False | |
| Enum | 패키지명 포함 전체 이름 사용 | jpabook.MemberType.Admin |
| 엔티티 타입 | 엔티티의 타입을 표현. 주로 상속과 관련하여 사용 | TYPE(m) = Member |
연산자 우선 순위
- 경로 탐색 연산: .
- 수학 연산: 단항 연산자 +, 단항 연산자 -, *, /, +, -
- 비교 연산: =, >, >=, <, <=, <>, [NOT] BETWEEN, [NOT] LIKE, [NOT] IN, IS [NOT] NULL, IS [NOT] EMPTY, [NOT] MEMBER [OF], [NOT] EXISTS
- 논리 연산: NOT, AND, OR
논리 연산과 비교식
- 논리 연산
- AND: 둘 다 만족하면 참
- OR: 둘 중 하나 만족하면 참
- NOT: 조건식의 결과 반대
- 비교식
-
= > >= < <= <>
-
Between, IN, Like, NULL 비교
- Between 식
- X [NOT] BETWEEN A AND B
- X는 A ~ B 사이 값이면 참(A, B 포함)
- IN 식
- X [NOT] IN (예제)
- X와 같은 값이 예제에 하나라도 있으면 참
- 예제에는 서브쿼리 사용 가능
- Like 식
- 문자 표현식 [NOT] LIKE 패턴값 [EXCAPE 이스케이프 문자]
- 문자 표현식과 패턴값을 비교
- %: 아무 값들이 입력되어도 됨(값이 없어도 됨)
- _: 한 글자는 아무 값이 입력되어도 되지만 값은 있어야 함
- NULL 비교식
-
{단일값 경로 입력 파라미터 } IS [NOT] NULL - NULL 인지 비교
-
컬렉션 식
- 컬렉션에만 사용하는 특별한 기능
-
컬렉션에선 컬렉션 식 외에 다른건 못 씀
- 빈 컬렉션 비교식
- { 컬렉션 값 연관 경로 } IS [NOT] EMPTY
- 컬렉션에 값이 비었으면 참
- 컬렉션의 멤버 식
- {엔티티나 값} [NOT] MEMBER [OF] {컬렉션 값 연관 경로}
- 엔티티나 값이 컬렉션에 포함되어 있으면 참
스칼라 식
-
숫자, 문자, 날짜, case, 엔티티 타입(엔티티의 타입 정보) 같은 기본적인 타입(스칼라)에 사용하는 식
- 수학 식
- +, -: 단항 연산자
- *, /, +, -: 사칙연산
- 문자 함수
| 함수 | 설명 | 예제 | ||
|---|---|---|---|---|
| CONCAT(문자1, 문자2, …) | 문자 합침. (HQL에선 | 로도 사용 가능) | CONCAT(‘A’, ‘B’) = AB | |
| SUBSTRING(문자, 위치[, 길이]) | 위치부터 시작해 길이만큼 문자 구함. 길이 값 없으면 나머지 전체 길이 의미 | SUBSTRING(‘ABCDEF’, 2, 3) = BCD | ||
| TRIM([[LEADING | TRAILING | BOTH] [트림 문자] FROM] 문자) | LEADING: 왼쪽만, TRAILING: 오른쪽만, BOTH:양쪽 다 트림 문자 제거(기본값은 BOTH, 트림 문자의 기본값은 공백(SPACE)) | TRIM(‘ ABC ‘) = ‘ABC’ |
| LOWER(문자) | 소문자화 | LOWER(‘ABC’) = ‘abc’ | ||
| UPPER(문자) | 대문자화 | UPPER(‘abc’) = ‘ABC’ | ||
| LENGTH(문자) | 문자 길이 | LENGTH(‘abc’) = 3 | ||
| LOCATE(찾을 문자, 원본 문자[, 검색시작위치]) | 검색시작위치부터 문자를 검색. 1부터 시작, 못찾으면 0 반환 | LOCATE(‘DE’, ‘ABCDEFG’) = 4 |
- 수학 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| ABS(수학식) | 절대값 | ABS(-10) = 10 |
| SQRT(수학식) | 제곱근 | SQRT(4) = 2.0 |
| MOD(수학식, 나눌 수) | 나머지 | MOD(4, 3) = 1 |
| SIZE(컬렉션 값 연관 경로식) | 컬렉션 크기 | SIZE(t.members) |
| INDEX(별칭) | LIST 타입 컬렉션의 위치값 구함(@OrderColumn 사용하는 LIST 타입일 떄만 사용 가능) | t.members m WHERE INDEX(m) > 3 |
- 날짜 함수
- CURRENT_DATE: 현재 날짜
- CURRENT_TIME: 현재 시간
- CURRENT_TIMESTAMP: 현재 날짜 시간
CASE 식
- 특정 조건에 따라 분기할 떄 사용
- 기본 CASE
CASE
{WHEN <조건식> THEN <스칼라식>}+
ELSE <스칼라식>
END
// 예제
SELECT
CASE
WHEN m.age <= 10 then '학생요금'
WHEN m.age >= 60 then '경로요금'
ELSE '일반요금'
END
FROM Member m
- 심플 CASE
- 조건식 사용 X, 문법 단순
- 자바의 switch case 문과 비슷
CASE <조건대상>
{WHEN <스칼라식1> THEN <스칼라식2>}+
ELSE <스칼라식>
END
// 예제
SELECT
CASE t.name
WHEN 'teamA' then '인센티브110%'
WHEN 'teamB' then '인센티브120%'
ELSE '인센티브105%'
END
FROM Team t
- COALESCE
- COALESCE(<스칼라식> {,<스칼라식>}+)
- 스칼라식을 차례로 조회해서 null 아니면 반환
SELECT COALESCE(m.username, 'unknown member') FROM Member m // m.username null 이면 'unknown member' 반환
- NULLIF
- NULLIF(<스칼라식>, <스칼라식>)
- 두 값 같으면 null, 다르면 첫 번째 값 반환
SELECT NULLIF(m.username, 'admin') FROM Member m // m.username이 'admin' 이면 null, 나머진 m.username 값 반환
10.2.11 다형성 쿼리
- JPQL로 부모 엔티티 조회시 자식 엔티티도 함께 조회
코드
@Entity
@Inheritance(startegy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {...}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
...
private String author;
}
// Album, Movie ...
...
TYPE
- 엔티티의 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용
// Item 중 Book, Movie 조회
// JPQL
SELECT i
ROM Item i
WHERE TYPE(i)
IN (Book, Movie)
// SQL
SELECT i
FROM Item i
WHERE i.DTYPE
IN ('B', 'M')
TREAT
- JPA 2.1 에 추가된 기능
- 자바의 타입 캐스팅과 유사함
- 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
- 표준은 FROM, WHERE 절에서 사용 가능, 하이버네이트는 SELECT 절에서도 사용 가능
// 부모인 Item, 자식인 Book
// Item 을 Book 타입처럼 다뤄서 author 필드 접근
// JPQL
SELECT i
FROM i
WHERE TREAT(i AS Book).author = 'kim'
// SQL
SELECT i.*
FROM Item i
WHERE i.DTYPE = 'B'
AND i.author = 'kim
10.2.12 사용자 정의 함수 호출
- JPA 2.1 부터 지원
- function_invocation::=FUNCTION(function_name {, function_arg}*)
SELECT FUNCTION('group_concat', i.name) FROM Item i- 하이버네이트 구현체 사용시 아래 코드와 같이 방언 클래스(H2Dialect) 상속, 구현하고 사용할 DB 함수 미리 등록하고
hibernate.dialect에 해당 방언 등록해야 함- 하이버네이트 구현체 사용시 위 예제를 다음과 같이 축약 가능
SELECT group_concat(i.name) FROM Item i
- 하이버네이트 구현체 사용시 위 예제를 다음과 같이 축약 가능
코드
// 방언 클래스 상속
public class MyH2Dialect extends H2Dialect {
public MyH2Dialect() {
registerFunction("group_concat",
new StandardSQLFunction("group_concat", StrandardBasicTypes.STRING));
}
}
// 상속한 방언 클래스 등록
<property name="hibernate.dialect" value=hello.MyH2Dialect" />
10.2.13 기타 정리
- enum은 = 비교 연산만 지원
- 임베디드 타입은 비교 지원 X
EMPTY STRING
- JPA 표준은 ‘‘를 길이 0인 Empty String 으로 정함
- DB에 따라 NULL 로 사용하는 곳도 있으므로 확인 후 사용
NULL 정의
- 조건 만족 데이터 하나도 없으면 NULL
- NULL 은 unknown value
- NULL 과의 모든 수학적 계산 결과는 NULL
- NULL == NULL 은 unknown value
- NULL is NULL 은 참
| AND | T | F | U |
|---|---|---|---|
| T | T | F | U |
| F | F | F | F |
| U | U | F | U |
| OR | T | F | U |
|---|---|---|---|
| T | T | T | T |
| F | T | F | U |
| U | T | U | U |
| NOT | |
|---|---|
| T | F |
| F | T |
| U | U |
10.2.14 엔티티 직접 사용
기본 키 값
- JPQL에서 엔티티 객체 직접 사용시 SQL에서는 해당 엔티티의 기본 키 값을 사용
SELECT COUNT(m.id) FROM Member m // 엔티티의 id 사용
SELECT COUNT(m) FROM Member m // 엔티티 직접 사용
- 두 번쨰 count(m)에서 엔티티 별칭 넘겨줘서 엔티티 직접 사용함
- 이렇게 하면 SQL 변환시 해당 엔티티 기본 키 사용하게 바뀜
- ∴ 위 두 예제는 동일한 쿼리로 변환됨
SELECT count(m.id) AS cnt
FROM Member m
외래 키 값
Team team = em.find(Team.class, 1L);
String qlString = "SELECT m FROM Member m WHERE m.team = :team"; // m.team_id 사용하도록 변환됨
List resultList = em.createQuery(qlString)
.setParameter("team", team)
.getResultList();
m.team이m.team_idfk 와 매핑되어 있으므로m.team_id사용하도록 변환됨
10.2.15 Named 쿼리: 정적 쿼리
- JPQL 쿼리는 크게 동적, 정적 쿼리로 구분 가능
- 동적 쿼리: ```em.createQuery(“SELECT …”) 처럼 JPQL을 문자로 오나성해서 직접 넘기는 것. 런타임에 특정 조건 따라 동적으로 구성 가능
- 정적 쿼리: 미리 정의한 쿼리에 이름 부여해서 필요할때 사용하는 쿼리(Named 쿼리). 한번 정의하면 변경 못함
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법 체크 후 미리 파싱해둠
- ∴ 오류 확인 빠르고 파싱된 결과 재사용하여 성능상 이점 있음
- 또한 변하지 않는 정적 SQL 생성되어 DB 조회 성능 최적화에도 도움됨
@NamedQuery어노테이션으로 자바 코드에 작성하거나 XML 문서에 작성 가능
Named 쿼리를 어노테이션에 정의
// Named 쿼리 정의
@Entity
@NamedQuery(
name = "Member.findByUsername", // Named 쿼리 이름
query = "SELECT m FROM Member m WHERE m.username = :username" // Named 쿼리로 사용할 쿼리
)
/*
@NamedQueries({ // named 쿼리 여러개 쓰려면 @NamedQueries 어노테이션 쓰면 됨
@NamedQuery(
name = "Member.findByUsername", // Named 쿼리 이름
query = "SELECT m FROM Member m WHERE m.username = :username" // Named 쿼리로 사용할 쿼리
),
@NamedQuery(
name = "Member.count", // Named 쿼리 이름
query = "SELECT COUNT(m) FROM Member m" // Named 쿼리로 사용할 쿼리
)
})
*/
public class Member {
...
}
...
// Named 쿼리 사용
public List<Member> findByUsername(EntityManager em, String username) {
return em.createNamedQuery("Member.findByUsername", Member.class) // EntityManger::createNamedQuery 메소드에 사용할 named 쿼리 이름 넣어서 사용
.setParameter("username", username)
.getResultList();
}
Named 쿼리를 XML에 정의
- 자바에서 멀티라인 문자 쓰는건 불편한데 xml 로 쓰면 편리함
- 그래서 named 쿼리 작성할 때 xml 쓰는게 좀 더 편함
- 아래와 같이 xml 에 named 쿼리 정의 후 해당 xml 파일 인식할 수 있도록 persistence.xml 파일에 설정정보 추가
- META-INF/orm.xml 은 JPA가 기본 매핑파일로 인식해서 별도 설정 필요없음
- 아래 예제처럼 파일 이름이나 경로가 다를 때 persistence.xml 파일에 설정 정보 추가해줘야 함
- XML과 어노테이션에 동일 설정 있으면 XML이 우선권 가짐
<!-- META-INF/ormMember.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm" version="2.1">
<named-query name="Member.findByUsername">
<query><CDATA[
SELECT m
FROM Member m
WHERE m.username = :username
]></query>
</named-query>
<named-query name="Member.count">
<query>SELECT COUNT(m) FROM Member m</query>
</named-query>
</entity-mappings>
...
<!-- META-INF/persistence.xml -->
...
<persistence-unit name="jpabook" >
<mapping-file>META-INF/ormMember.xml</mapping-file>
...
XML에서 &, <, > 는 예약 문자라 못씀
대신&,<,>써야 함
<![CDATA[...]]>쓰면 예약 문자도 그냥 사용 가능
Criteria
- JPQL을 자바 코드로 작성하도록 도와주는 빌더 클래스 API
- 문법 오류를 컴파일 단계에서 잡을 수 있고 동적 쿼리 안전하게 생성할 수 있음
- 대신 코드가 복잡하고 장황해 직관적 이해가 힘듬
10.3.1 Criteria 기초
/** JPQL
* SELECT m
* FROM Member m
* WHERE m.username='member1'
* ORDER BY m.age DESC
*/
// EntityManager 또는 EntityManagerFactory에서 Creatria Builder 얻음
CriteriaBuilder cb = em.getCriteriaBuilder();
// Criteria 생성, 반환 타입 지정
CriteriaQuery<Member> cq = cb.createQuery(Member.class);
// FROM 절 생성. 반환된 값 m은 Criteria에서 사용하는 특별한 alias
Root<Member> m = cq.from(Member.class);
// 검색 조건 정의
Predicate usernameEqual = cb.equal(m.get("username"), "member1");
// 정렬 조건 정의
javax.persistence.criteria.Order ageDesc = cb.desc(m.get("age"));
// 쿼리 생성
// 위에서 만든 검색, 정렬 조건을 각각 where, orderBy 에 넣어서 원하는 쿼리 만듬
cq.select(m) // SELECT 절 생성
.where(usernameEqual) // WHERE 절 생성
.orderBy(ageDesc); // ORDER BY 절 생성
// JPQL 쓸때와 동일하게 EntityManager::createQuery 호출해서 쿼리 만들고 실행
List<Member> resultList = em.createQuery(cq).getResultList();
- 쿼리 루트
Root<Member> m = cq.from(Member.class);에서 m이 쿼리 루트- 쿼리 루트는 조회의 시작점
- Createria에서 사용되는 특별한 alias, JPQL의 alias 라 보면 됨
- alias는 엔티티에만 부여 가능
- 경로 표현식
m.get("team").get("name")은 JPQLm.team.name과 동일m.get()사용할 때 String 의 경우엔 필요없지만 Integer 등일 때는m.<Integer>get()과 같이 제네릭으로 타입 정보 줘야 함
10.3.2 Criteria 쿼리 생성
CriteriaBuilder.createQuery()메소드로 CriteriaQuery 생성- CreiteriaQuery 생성시 파라미터로 쿼리 결과에 대한 반환 타입 지정 가능
- 이 때 반환 타입을 지정해두면
em.createQuery()호출시 따로 지정 안해줘도 됨 - 반환 타입 지정 못하거나 둘 이상이면 Object 로 반환받으면 됨
- 이 때 반환 타입을 지정해두면
10.3.3 조회
조회 대상을 한 건, 여러 건 지정
- 조회 대상 하나만 지정할 땐
cq.select(m) // SELECT m
- 여러 건 지정시에는 multiselect 사용
cq.multiselect(m.get("username"), m.get("age")); // SELECT m.username, m.age- 또는 아래와 같이
CriteriaBuilder::array()써도 됨cq.select(cb.array(m.get("username"), m.get("age")));
DISTINCT
- select, multiselect 다음에
distinct(true)추가하면 됨cq.multiselect(m.get("username"), m.get("age")).distinct(true); // SELECT DISTINCT m.username, m.age
NEW, construct()
- JPQL에서의
SELECT NEW 생성자()구문이 Criteria 에서는CriteriaBuilder::construct(클래스 타입, ...)cq.select(cb.construct(MemberDTO.class, m.get("username"), m.get("age"))); // SELECT NEW jpabook.domain.MemberDTO(m.username, m.age)
- Criteria는 코드를 직접 다루기 때문에 JPQL 처럼 패키지명 다 안쓰고
MemberDTO.class처럼 간략하게 써도 됨
튜플
- Crietria 에서 제공하는 특별한 반환 객체
- Map 과 비슷함
- 튜플로 받으려면
cb.createTupleQuery()또는cb.createQuery(Tuple.class)로 Criteria 생성 - select 메소드에서 튜플 검색키로 사용할 전용 alias 필수로 할당해야 함
- 선언한 tuple alias로 데이터 조회할 수 있음
- 이름 기반이기 때문에 Ojbect[] 로 반환받는거보다 안전함
- 튜플로 엔티티도 조회할 수 있음
코드
// SELECT m.username, m.age FROM Member m
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Tuple> cq = cb.createTupleQuery(); // cb.createQuery(Tuple.class);
Root<Member> m = cq.from(Member.class);
cq.multiselect(
m.get("username").alias("username"), // 튜플에서 쓸 튜플 alias
m.get("age").alias("age")
);
TypedQuery<Tuple> query = em.createQuery(cq);
List<Tuple> resultList = query.getResultList();
for (Tuple tuple: resultList) {
String username = tuple.get("username", String.class); // 위에서 지정한 tuple alias 로 데이터 조회
Integer age = tuple.get("age", Integer.class);
}
...
// 튜플과 엔티티 조회
// cq.multiselect(...) 대신 아래처럼 cq.select(cb.tuple(...)) 써도 같은 동작 함
cq.select(cb.tuple(
m.alias("m"), // Member entity 조회, alias m (쿼리 루트인 m과 관련 없음)
m.get("username").alias("username") // 단순 값 조회, alias username
));
TypedQuery<Tuple> query = em.createQuery(cq);
List<Tuple> resultList = query.getResultList();
for (Tuple tuple: resultList) {
Member member = tuple.get("m", Member.class);
String username = tuple.get("username", String.class);
}
10.3.4 집합
GROUP BY
cq.groupBy(m.get("team").get("name")) // GROUP BY m.team.name
HAVING
cq.having(cb.gt(minAge, 10)) // HAVING min(m.age) > 10CriteriaBuilder::gt()===CriteriaBuilder::greaterThan()
10.3.5 정렬
cq.orderBy(cb.desc(m.get("age"))); // ORDER BY m.age DESC
10.3.6 조인
join()메소드,JoinType클래스 사용- fetch join은
fetch()메소드 사용
public enum JoinType {
INNER // inner join. JoinType 지정 안하면 default INNER
, LEFT // left outer join
, RIGHT // right outer join
}
코드
/** JPQL
* SELECT m, t
* FROM Member m
* INNER JOIN m.team t
* WHERE t.name = 'teamA';
*/
Root<Member> m = cq.from(Member.class);
Join<Member, Team> t = m.join("team", JoinType.INNER); // 쿼리 루트(m)에서 Member, Team 조인. t는 조인한 team 의 alias
cq.multiselect(m, t)
.where(cb.equal(t.get("name"), "teamA"));
...
// FETCH join
Root<Member> m = cq.from(Member.class);
m.fetch("team", JoinType.LFET); // join 대신 fetch 메소드 사용
cq.select(m2);
10.3.7 서브 쿼리
- 간단한 서브 쿼리
- 메인 쿼리와 서브 쿼리가 서로 무관한 경우
/** JPQL
* SELECT m
* FROM Member m
* WHERE m.age >= (
* SELECT AVG(m2.age)
* FROM Member m2
* )
*/
// 서브 쿼리 생성
SubQuery<Double> subQuery = mainQuery.subquery(Double.class);
Root<Member> m2 = subQuery.from(Member.class);
subQuery.select(cb.avg(m2.<Integer>get("age")));
// 메인 쿼리 생성(위에서 생성한 subQuery 갖다 씀)
Root<Member> m = mainQuery.from(Member.class);
mainQuery.select(m)
.where(cb.ge(m.<Integer>get("age"), subQuery));
- 상호 관련 서브 쿼리
- 메인 쿼리와 서브 쿼리 간 서로 관련 있을 경우
- 서브 쿼리에서 메인 쿼리 정보 사용하려면 메인 쿼리에서 사용한 별칭 얻어야 함
- 메인 쿼리의 Root 나 Join 을 통해 생성된 별칭 받아서 사용
CriteriaQuery::correlate(...)메소드 사용해서 메인 쿼리의 alias를 서브쿼리에서 사용할 수 있음
코드
/** JPQL
* SELECT m
* FROM Member m
* WHERE EXISTS (
* SELECT t
* FROM m.team t
* WHERE t.name="teamA"
* )
*/
// 서브 쿼리에서 사용되는 메인 쿼리의 alias m
Root<Member> m = mainQuery.from(Member.class);
// 서브 쿼리 생성
Subquery<Team> subQuery = mainQuery.subquery(Team.class);
Root<Member> subM = subQuery.correlate(m); // main query의 alias 가져옴. main query 의 m을 sub query 에선 subM으로 사용
Join<Member, Team> t = subM.join("team");
subQuery.select(t)
.where(cb.equal(t.get("name"), "teamA"));
// 메인 쿼리 생성
mainQuery.select(m)
.qhere(cb.exists(subQuery));
List<Member> resultList = em.createQuery(mainQuery).getResultList();
10.3.8 IN 식
in(...).value(...).value(...)...형태cq.where(cb.in(m.get("username")).value("member1").value("member2")); // WHERE m.username IN ("member1", "meber2")
10.3.9 CASE 식
selectCase(),when(),otherwise()메소드 사용
/** JPQL
* SELECT m.username,
* CASE
* WHEN m.age >= 60 THEN 600
* WHEN m.age <= 15 THEN 500
* ELSE 1000
* END
* FROM Member m
*/
Root<Member> m = cq.from(Member.class);
cq.multiselect(
m.get("username"),
cb.selectCase()
.when(cb.ge(m.<Integer>get("age"), 60), 600)
.when(cb.le(m.<Integer> get("age"), 15), 500)
.otherwise(1000)
);
10.3.10 파라미터 정의
- JPQL에서
:param으로 파라미터 정의한 것 처럼 Criteria도 파라미터 정의 가능CriteriaBuilder::parameter(타입, 파라미터 이름)메소드로 파라미터 정의setParameter(파라미터 이름, 파라미터 값)으로 사용할 값 바인딩
/** JPQL
* SELECT m
* FROM Member m
* WHERE m.username = :usernameParam
*/
Root<Member> m = cq.from(Member.class);
cq.select(m)
.where(cb.equal(m.get("username"), cb.parameter(String.class, "usernameParam"))); // 파라미터 정의
List<Member> resultList = em.createQuery(cq)
.setParameter("usernameParam", "member1") // 파라미터 바인딩
.getResultList();
10.3.11 네이티브 함수 호출
CriteriaBuilder::function(...)메소드 쓰면 됨
/** JPQL
* SELECT SUM(m.age)
* FROM Member m
*/
Root<Member> m = cq.from(Member.class);
Expression<Long> function = cb.function("SUM", Long.class, m.get("age")); // SUM SQL 함수 호출
cq.select(function);
10.3.12 동적 쿼리
- 다양한 검색 조건 따라 실행 시점에 쿼리 생성하는 것
- 파라미터 바인딩처럼 파라미터 값만 바뀌는게 아니라 쿼리 자체가 달라짐
- ex) 날짜, 제목, 글 내용 가지고 검색 가능한 게시판 있을 때 제목만 입력하면 제목만으로 쿼리, 날짜까지 입력하면 제목, 날짜로 쿼리하는 등
- 문자 기반인 JPQL 로 동적 쿼리 작성 시 버그 날 확률도 높고 불편함
- Criteria는 코드기반이라 좀 낫긴 한데 그래도 코드 읽기 힘들긴 함
- 최소한 공백, where, and 위치로 인한 에러는 안남
코드
/** JPQL
* SELECT m
* FROM Member m
* INNER JOIN m.team t
* WHERE m.age = 10
* AND t.name = "teamA"
*/
// 검색 조건
Integer age = 10;
String username = null;
String teamName = "teamA";
// Criteria 동적 쿼리 생성
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Member> cq = cb.createQuery(Member.class);
Root<Member> m = cq.from(Member.class);
Join<Member, Team> t = m.join("team");
List<Predicate> criteria = new ArrayList<Predicate>();
if (age != null) criteria.add(cb.equal(m.<Integer>get("age"), cb.parameter(Integer.class, "age")));
if (username != null) criteria.add(cb.equal(m.get("username"), cb.parameter(String.class, "username")));
if (teamName != null) criteria.add(cb.equal(t.get("name"), cb.parameter(String.class, "teamName")));
cq.select(m);
.where(cb.and(criteria.toArray(new Predicate[0])));
TypedQuery<Member> query = em.createQuery(cq);
if (age != null) query.setParameter("age", age);
if (username != null) query.setParameter("username", username);
if (teamName != null) query.setParameter("teamName", teamName);
List<Member> resultList = query.getResultList();
10.3.13 함수 정리
- Criteria는 JPQL 빌더 역할을 하므로 JPQL 함수를 코드로 지원
- 대부분 CriteriaBuilder 에 정의되어 있음
10.3.14 Criteria 메타 모델 API
- Criteria는 코드 기반이지만
m.get("age");에서의 “age” 처럼 문자가 사용됨 - 이로 인해서 컴파일 시점에 발견하지 못하는 에러 생길 수 있음
- 메타 모델 API 사용하면 이런 부분도 코드로 작성 가능
- 메타 모델 클래스를 코드 자동 생성기를 통해 생성해서 사용하면 됨
- 코드 생성기는 보통 maven, gradle 등의 빌드 도구를 써서 실행
- 디펜던시랑 플러그인 설정 후 빌드 도구 compile 하면 메타 모델 클래스 생성됨
10.4 QueryDSL
- Criteria 처럼 JPQL 빌더 역할 함
10.4.1 QueryDSL 설정
- pom.xml 추가
- querydsl-jpa: QueryDSL JPA 라이브러리
- querydsl-apt: Query Type(Q) 생성에 필요한 라이브러리
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>3.6.3</version>
</dependency>
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>3.6.3</version>
<scope>provided</scope>
</dependency>
- 환경설정
- queryDSL 사용시 Creiteria의 메타 모델 클래스처럼 엔티티를 기반으로한 Query Type 이라는 쿼리용 클래스 생성해야 함
- 이를 위해 Query Type 생성용 플러그인을 pom.xml 에 추가
- 설정 다 하고 mvn compile 돌리면 아래에서 지정한 target/generated-sources 에 Q로 시작하는 쿼리 타입들이 생성됨
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<excutions>
<excution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.mysema.query.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</excution>
</excutions>
</plugin>
</plugins>
</build>
10.4.2 시작
/**JPQL
* SELECT m
* FROM Member m
* WHERE m.name = 'member1'
* ORDER BY m.name DESC
*/
EntityManager em = emf.createEntityManager();
// 엔티티 매니저로 JPAQuery 객체 생성
JPAQuery query = new JPAQuery(em);
// 사용할 Query Type 생성, JPQL에서 사용할 alias 부여
QMember qMember = new QMember("m");
List<Member> members = query
.from(qMember)
.where(qMember.name.eq("member1"))
.orderBy(qMember.name.desc())
.list(qMember);
기본 Q 생성
- Query Type(Q)는 기본 인스턴스를 보관하고 있어서 alias 지정 안하고 걍 기본 인스턴스 써도 됨
QMember qMember = QMember.meber; // 기본 인스턴스 사용
- 하지만 같은 엔티티 조인하거나 서브쿼리에 사용하면 같은 alias 사용되므로 직접 지정해서 써야 함
QMember qMember = new QMember("m"); // alias 직접 지정
- Q의 기본 인스턴스를 static 으로 임포트하면 아래와 같이 더 편리하게 코드 작성 가능
// Query Type 의 기본 인스턴스를 static으로 import
import static jpabook.jpashop.domain.QMember.member;
public void basic() {
EntityManager em = emf.createEntityManager();
JPAQuery query = new JPAQuery(em);
List<Member> members = query
.from(member) // 기본 인스턴스 걍 갖다 씀
.where(member.name.eq("member1"))
.orderBy(member.name.desc())
.list(member);
}
10.4.3 검색 조건 쿼리
- where 절에는 and, or 사용 가능
.where(item.name.eq("itemA").and(item.price.gt(20000)))
- 다음과 같이 and, or 없이 여러 검색 조건 넣으면 자동으로 and 연산 됨
.where(item.name.eq("itemA"), item.price.gt(20000))
- 이 외에도 between, contains, startWith 등 제공
10.4.4 결과 조회
- 쿼리 작성 완료 후 결과 조회 메소드 호출할 때 실제 DB 조회함
- 보통
uniqueResult()나list()사용하고 파라미터로 프로젝션 대상 넘겨줌- uniqueResult()
- 조회 결과 단건일 때 사용
- 결과 없으면 null, 두 개 이상이면 예외 발생
- singleResult()
- 결과가 두 개 이상이면 그중 처음 데이터를 반환
- list()
- 결과가 두 개 이상일 때 사용
- 결과 없으면 빈 컬렉션 반환
- uniqueResult()
10.4.5 페이징과 정렬
- 정렬은 orderBy와 Q 가 제공하는
asc(),desc()메소드 사용.orderBy(item.price.desc(), item.stockQuantity.asc())
- 페이징은
offset(),limit()메소드 사용.offset(10).limit(20)- 이거 대신에
restrict()메소드에com.mysema.query.QueryModifiers를 파라미터로 사용해도 됨restrict(new QueryModifiers(20L, 10L)) // 각각 limit, offset
- 실제 페이징 처리 하려면 검색된 전체 데이터 수 알아야 하므로
list()대신listResults()사용listResults()사용시 전체 데이터 조회 위한 count 쿼리를 한 번 더 실행함
SearchResults<Item> result = query
.from(item)
.where(item.price.gt(10000))
.offset(10).limit(20)
.listResults(item);
long total = result.getTotal(); // 검색된 전체 데이터 수
long limit = result.getLimit(); // 조회할 때 쓴 limit
long offset = result.getOffset(); // 조회할 때 쓴 offset
List<Item> results = result.getResults(); // 조회된 데이터
10.4.6 그룹
- groupBy 사용, 그룹화된 결과 제한하려면 having 사용
.groupBy(item.price).having(item.price.gt(1000))
10.4.7 조인
- innerJoin, leftJoin, rightJoin, fullJoin 사용 가능
- jPAL의 on, 성능 최적화를 위한 fetch 조인도 가능
- 첫 번째 파라미터에 조인 대상, 두 번째 파라미터에 alias 로 사용할 Query Type 지정
join(조인 대상, alias 로 사용할 쿼리 타입)
- join에 on 사용
.leftJoin(order.orderItems, orderItem).on(orderItem.count.gt(2))
- fetch join
.innerJoin(order.member, member).fetch().leftJoin(order.orderItems.orderItem).fetch()
- from 절에 여러 조인 사용하는 세타 조인 방법
.from(order, member)
10.4.8. 서브 쿼리
com.mysema.query.jpa.JPASubQuery를 생성해서 사용- 서브 쿼리 결과 하나면
unique(), 여러 건이면list()
// 결과 한 건
QItem item = QItem.item;
QItem itemSub = new QItem("itemSub");
query
.from(item)
.where(item.price.eq(
new JPASubQuery()
.from(itemSub)
.unique(itemSub.price.max())
)).list(item);
// 결과 여러 건
QItem item = QItem.item;
QItem itemSub = new QItem("itemSub");
query
.from(item)
.where(item.price.eq(
new JPASubQuery()
.from(itemSub)
.where(item.name.eq(itemSub.name))
.list(itemSub)
)).list(item);
10.4.9 프로젝션과 결과 반환
- SELECT 절에 조회 대상을 지정 하는 것 => 프로젝션
- QueryDSL 에서는 결과 조회 메소드의 파라미터로 프로젝션 대상 지정
프로젝션 대상 하나
- 해당 타입으로 반환
List<String> result = query.from(item).list(item.name); // 프로젝션 대상이 name 하나라 String 으로 바로 반환
여러 컬럼 반환과 튜플
- ```com.mysema.query.Tuple`` 이라는 Map 과 유사한 내부 타입 사용
- 조회 결과는
tuple.get()메소드에 조회한 Query Type 지정하면 됨
QItem item = QItem.item;
List<Tuple> result = query
.from(item)
.list(item.name, item.price); // === .list(new QTuple(item.name, item.price));
for (Tuple tuple: result) {
System.out.println("name = " + tuple.get(item.name));
System.out.println("price = " + tuple.get(item.price));
}
빈 생성
- 쿼리 결과를 엔티티가 아닌 다른 특정 객체로 받으려면 Bean population 기능을 사용하면 됨
- QueryDSL 은 객체를 생성하는 다양한 방법을 제공
- 프로퍼티 접근(Setter)
- 필드 직접 접근
- 생성자 사용
- 원하는 방법 지정하려면
com.mysema.query.types.Projections사용
// DTO
public class ItemDTO {
private String username;
private int price;
// constructor, getter, setter...
...
}
...
QItem item = QItem.item;
// 프로퍼티 접근(Setter)
// Setter 사용해서 값 채워줌
List<ItemDTO> result = query
.from(item)
.list(
Projections.bean(ItemDTO.class, item.name.as("username"), item.price) // 쿼리 결과와 매핑할 프로퍼티 이름 다르면 as 사용
);
// field 직접 접근
// Projections.fields() 메소드 사용시 필드에 직접 접근해서 값 채워줌
// 필드를 private으로 설정해도 동작함
List<ItemDTO> result = query
.from(item)
.list(
Projections.fields(ItemDTO.class, item.name.as("username"), item.price)
);
// constructor 사용
// 생성자 이용해서 값 채움
// 지정한 프로젝션과 파라미터 순서 동일한 생성자가 필요
List<ItemDTO> result = query
.from(item)
.list(
Projections.constructor(ItemDTO.class, item.name, item.price)
);
DISCTINCT
query.distinct().from(item)...
10.4.10 수정, 삭제 배치 쿼리
- QueryDSL도 수정, 삭제 같은 배치 쿼리 지원
- JPQL 배치 쿼리와 같이 영속성 컨텍스트를 무시하고 DB에 직접 쿼리
// 수정 배치 쿼리 예시
JPAUpdateClause updateClause = new JPAUpdateClause(em, item); // 수정 배치 쿼리는 JPAUpdateClause 사용
long count = updateCluase
.where(item.name.eq("itemA"))
.set(item.price, item.price.add(100))
.execute();
...
// 삭제 배치 쿼리 예시
JPADeleteClause deleteClause = new JPADeleteClause(em, item); // 삭제 배치 쿼리는 JPADeleteClause 사용
long count = deleteClause
.where(item.name.eq("itemA"))
.execute();
10.4.11 동적 쿼리
com.mysema.query.BooleanBuilder사용하면 특정 조건에 따른 동적 쿼리 생성 가능
SearchParam param = new SearchParam();
param.setName("itemA")
param.setPrice(10000);
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if (StringUtils.hasText(param.getName())) {
builder.and(item.name.contains(param.getName()));
}
ig (param.getPrice() != null) {
builder.and(item.price.gt(param.getPrice()));
}
List<Item> result = query
.from(item)
.where(builder)
.list(item);
10.4.12 메소드 위임
- delegate methods 기능 사용하면 Query Type 에 검색 조건 직접 정의 가능
- 우선 static method를 만들고
@QueryDelegate어노테이션에 속성으로 이 기능을 적용할 엔티티를 지정 - static method 의 첫 번째 파라미터에는 대상 엔티티의 Query Type 을 지정하고 나머지는 필요한 파라미터를 정의
- 우선 static method를 만들고
- String, Date 등 자바 기본 내장 타입에도 메소드 위임 기능 사용 가능
// delegate methods 기능으로 검색 조건 정의
public class ItemExpression {
@QueryDelegate(Item.class)
public static BooleanExpression isExpensive(QItem item, Integer price) {
return item.price.gt(price);
}
}
...
// 실제 Query Type 에 생성된 결과
public class QItem extends EntityPathBase<Item> {
...
public com.mysema.query.types.expr.BooleanExpression isExpensive(Intger price) {
return ItemExpression.isExpensive(this.price);
}
...
}
...
// delegate methods 기능 사용
List<Item> result = query
.from(item)
.where(item.isExpensive(30000))
.list(item);
10.5 네이티브 SQL
- JPQL은 특정 DB에 종속적인 기능은 지원 X, 대신 JPA는 특정 DB 종속적 기능 사용할 수 있는 다양한 방법 열어두었고 구현체들은 더 다양한 방법 지원함
- 특정 데이터베이스만 지원하는 함수
- JPQL에서 네이티브 SQL 함수 호출 가능(JPA 2.1)
- 하이버네이트는 DB 방언에 각 DB 종속적 함수들 정의해두었음. 직접 호출할 함수 정의도 가능
- 특정 데이터베이스만 지원하는 SQL 쿼리 힌트
- 하이버네이트 등 몇 JPA 구현제들이 지원
- 인라인 뷰(From 절에서 사용하는 서브 쿼리), UNION, INTERSECT
- 일부 JPA 구현체들이 지원
- stored procedure
- JPQL에서 스토어드 프로시저 호출 가능(JPA 2.1)
- 특정 데이터베이스만 지원하는 문법
- 오라클 CONNECT BY 처럼 너무 종속적인건 지원 안함
- 이럴 땐 네이티브 SQL 사용해야 함
- 특정 데이터베이스만 지원하는 함수
- 여러 이유로 JPQL 사용 못할 때 직접 SQL 사용할 수 있는 기능 => 네이티브 SQL
- JPQL 사용하면 JPA 가 SQL 생성
- 네이티브 SQL 사용하면 개발자가 직접 생성
- 네이티브 SQL 써도 JPA 가 지원하는 영속성 컨텍스트의 기능 그대로 사용할 수 있음
10.5.1 네이티브 SQL 사용
엔티티 조회
em.createNativeQuery(SQL, 결과 클래스)- 첫 번째 파라미터는 네이티브 SQL, 두 번째 파라미터는 조회할 엔티티 클래스의 타입
- JPQL과 거의 비스샇지만 실제 DB sql 사용하며 위치기반 파라미터만 지원함
String sql =
"SELECT id, age, name, team_id " +
"FROM member " +
"WHERE age > ?";
Query nativeQuery = em.createNativeQuery(sql, Member.class) // native SQL은 type 정보 줘도 TypeQuery 아니고 Query 임
.setParameter(1, 20);
List<Member> resultList = nativeQuery.getResultList();
값 조회
- 여러 값으로 조회하려면
em.createNativeQuery(SQL)처럼 두 번째 파라미터 사용 안하면 됨 - 이렇게 하면 조회한 값들이 Object[] 에 담겨서 반환됨
String sql =
"SELECT id, age, name, team_id " +
"FROM member " +
"WHERE age > ?";
Query nativeQuery = em.createNativeQuery(sql)
.setParameter(1, 10);
List<Object[]> resultList = nativeQuery.getResultList();
for (Object[] row: resultList) {
System.out.println("id = " + row[0]);
System.out.println("age = " + row[1]);
System.out.println("name = " + row[2]);
System.out.println("team_id = " + row[3]);
}
결과 매핑 사용
- 엔티티와 스칼라 값을 함께 조회하는 것처럼 매핑 복잡해지면
@SqlResultSetMapping을 정의해서 결과 매핑 사용해야 함
// 결과 매핑 정의
@Entity
@SqlResultSetMapping(name = "memberWithOrderCount",
entities = {@EntityResult(entityClass = Member.class)}, // 여러 엔티티랑 매핑 가능
columns = {@ColumnResult(name = "order_count")} // 여러 컬럼이랑 매핑 가능
)
public class Member { ... }
...
// Native SQL 쿼리
String sql =
"SELECT m.id age, name, team_id, i.order_count " +
"FROM member m " +
" LEFT JOIN " +
" (SELECT im.id, COUNT(*) AS order_count " +
" FROM orders o, member im " +
" WHERE o.member_id = im.id) i " +
" ON m.id = i.id";
Query nativeQuery = em.createNativeQuery(sql, "memberWithOrderCount"); // 위에서 정의한 결과 매핑 memberWithOrderCount 를 조회할 타입 파라미터로 사용
List<Object[]> resultList = nativeQuery.getResultList();
for (Object[] row: resultList) {
Member member = (Member) row[0];
BigInteger orderCount = (BigIntiger) row[1];
System.out.println("member = " + member);
System.out.println("orderCount = " + orderCount);
}
- 결과 매핑시
@FieldResult를 사용해서 엔티티의 필드명과 컬럼명을 직접 매핑할 수 있음 - 이걸로 설정한 건 엔티티의 필드에 설정한
@Column보다 우선됨 - 하나라도
@FieldResult쓰면 나머지 필드도 다 써야함 - 두 엔티티 조회 시 컬럼명 중복될 때도
@FieldResult사용- alias로 충돌하는 컬럼명 적당히 바꿔놓고
@FieldResult로 alias랑 엔티티 필드 매핑해주면 됨
- alias로 충돌하는 컬럼명 적당히 바꿔놓고
// 결과 매핑 정의
@SqlResultSetMapping(name = "OrderResults",
entities = {
@EntityResult(entityClass=com.acme.Order.class, fields = {
@FieldResult(name="id", column="order_id"),
@FieldResult(name="quantity", column="order_quantity"),
@FieldResult(name="item", column="order_item")
})
},
columns = {
@ColumnResult(name="item_name")
}
)
// Native SQL 쿼리
Query q = em.createNativeQuery(
"SELECT o.id AS order_id, " +
" o.quantity AS order_quantity, " +
" o.item AS order_item, " +
" i.name AS item_name " +
"FROM order o, item i " +
"WHERE (order_quantity > 25) " +
" AND (order_item = i.id_)", "OrderResults");
)
결과 매핑 어노테이션 (Result set mapping)
@SqlResultSetMapping속성
| 속성 | 기능 |
|---|---|
| name | 결과 매핑 이름 |
| entities | @EntityResult를 사용해서 엔티티를 결과로 매핑 |
| columns | @ColumnResult를 사용해서 컬럼을 결과로 매핑 |
@EntityResult속성
| 속성 | 기능 |
|---|---|
| entityClass | 결과로 사용할 엔티티 클래스 지정 |
| fields | @FieldResult를 사용해서 결과 컬럼을 필드와 매핑 |
| discriminatorColumn | 엔티티의 인스턴스 타입을 구분하는 필드(상속시 사용) |
@FieldResult속성
| 속성 | 기능 |
|---|---|
| name | 결과를 받을 필드명 |
| column | 결과 컬럼명 |
@CloumnResult속성
| 속성 | 기능 |
|---|---|
| name | 결과 컬럼명 |
10.5.2 Named 네이티브 SQL
- JPQL 처럼 Named Native SQL 로 정적 SQL 작성 가능
@NamedNativeQuery어노테이션으로 정의하거나 xml에 등록해서 사용- 일반적인 Native SQL 처럼
em.createNativeQuery()대신em.createNamedQuery()메소드를 사용함- TypedQuery 사용할 수 있음
// 어노테이션으로 등록
@Entity
@NamedNativeQuery(
name = "Member.memberSQL",
query =
"SELECT id, age, name, team_id " +
"FROM member " +
"WHERE age > ?",
resultClass = Member.class
)
public class Member { ... }
...
// 결과 매핑 사용
TypedQuery<Member> nativeQuery = em.createNamedQuery("Member.memberSQL", Member.class)
.setParamter(1, 20);
@NamedNativeQuery
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 네임드 쿼리 이름(필수) | |
| query | SQL 쿼리(필수) | |
| hints | 벤더 종속적인 hint(SQL 힌트가 아닌 JPA 구현체에 제공하는 힌트) | |
| resultClass | 결과 클래스 | |
| resultSetMapping | 결고 ㅏ매핑 사용 |
10.5.3 네이티브 SQL XML에 정의
- 어노테이션 대신 xml 에 다음과 같이 정의해서도 사용할 수 있음
- named native query, result set mapping 둘 다 가능
<named-native-query/>먼저 정의 후<result-set-mapping/>정의해야 함
<entity-mappings ...>
<named-native-query name="Member.memberWithOrderCountXml"
result-set-mapping="memberWithOrderCountResultMap" >
<query><CDATA[
SELECT m.id, age, name, team_id, i.order_count
FROM member m
LEFT JOIN (
SELECT im.id, COUNT(*) as order_count
FROM orders o, member im
WHERE o.member_id = im.id
) i
ON m.id = i.id
]></query>
</named-native-query>
<sql-result-set-mapping name="memberWithOrderCountResultMap">
<entity-result entity-class="jpabook.domain.Member" />
<column-result name="order_count" />
</sql-result-set-mapping>
</entity-mappings>
10.5.4 네이티브 SQL 정리
- 네이티브 SQL도 JPQL과 마찬가지로 Query, TypedQuery(named native query 사용시에만)를 반환
- ∴ 페이징 처리 API 등 JPQL API 그대로 사용 가능
10.5.5 스토어드 프로시저(JPA 2.1)
스토어드 프로시저 사용
em.createStoredProcedureQuery()메소드에 사용할 스토어드 프로시저 이름을 파라미터로 호출registerStoredProcedureParamter()메소드를 사용해서 프로시저에서 사용할 파라미터를 순서, 타입, 파라미터 모드 순으로 정의- 파라미터 모드
- IN: INPUT 파라미터
- INOUT: INPUT, OUTPUT 파라미터
- OUT: OUTPUT 파라미터
- REF_CURSOR: CURSOR 파라미터
- 파라미터 모드
# 첫 번째 파라미터로 값 입력받고 곱하기 2 해서 두 번째 파라미터로 결과 반환하는 프로시저 생성
DELIMITER //
CREATE PROCEDURE proc_multiply (INOUT inParam INT, INOUT outParam INT)
BEGIN
SET outParam = inParam * 2;
END //
// proc_multiply 프로시저 호출 (순서 기반 파라미터)
StoredProcedureQuery spq = em.createStoredProcedureQuery("proc_multiply");
spq.registerStoredProcedureParamter(1, Integer.class, ParamterMode.IN);
spq.registerStoredProcedureParamter(2, Integer.class, ParamterMode.OUT);
spq.setParamter(1, 100);
spq.execute();
Integer out = (Integer) spq.getOutputParamterValue(2);
System.out.println("out = " + out); // out = 200
...
// proc_multiply 프로시저 호출 (이름 기반 파라미터)
StoredProcedureQuery spq = em.createStoredProcedureQuery("proc_multiply");
spq.registerStoredProcedureParamter("inParam", Integer.class, ParamterMode.IN);
spq.registerStoredProcedureParamter("outParam", Integer.class, ParamterMode.OUT);
spq.setParamter("inParam", 100);
spq.execute();
Integer out = (Integer) spq.getOutputParamterValue(2);
System.out.println("out = " + out); // out = 200
Named 스토어드 프로시저 사용
- 스토어드 프로시저 쿼리에 이름 부여해서 사용하는 것
@NamedStoredProcedureQuery로 정의- name 속성으로 이름 부여
- procedureName 속성에 실제 호출할 프로시저 이름 설정
@StoredProcedureParameter사용해서 파라미터 정보 정의
- 둘 이상 정의하려면
@NamedStoredPRocedureQueries사용 - 어노테이션 대신 xml 로도 정의할 수 있음
// named stored procedure 정의
@Entity
@NamedStoredProcedureQuery(
name = "multiply",
procedureName = "proc_multiply",
paramter = {
@StoredProcedurePatameter(name = "inParam", mode = ParameterMode.IN, type = Intger.class),
@StoredProcedureParamter(name = "outParam", mode = ParameterMode.OUT, type = Integer.class)
}
)
public class Member { ... }
// 정의한 named stored procedure 호출
StoredProcedureQuery spq = em.createNamedStoredProcedureQuery("multiply");
spq.setParamter("inParam", 100);
spq.execute();
Integer out = (Integer) spq.getOutputParamterValue("outParam");
System.out.println("out = " + out);
<!-- xml에 named stored procedure 정의 -->
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm" version="2.1">
<named-stored-procedure-query name="multiply"
procedure-name="proc_multiply">
<paramter name="inParam" mode="IN" class="java.lang.Integer" />
<paramter name="outParam" mode="OUT" class="java.lang.Integer" />
</named-stored-procedure-query>
</entity-mappings>
10.6 객체지향 쿼리 심화
10.6.1 벌크 연산
- 여러 건을 한 번에 수정/삭제할 때 사용
executeUpdate()메소드를 사용하며, return 값으로 벌크 연산에 영향 받은 엔티티 건수 반환
// UPDATE 벌크 연산
String qlString =
"UPDATE Product p " +
"SET s.price = p.price * 1.1 " +
"WHERE p.stockAmount < :stockAmount";
int resultCounht = em.createQuery(qlString)
.setParamter("stockAmount", 10)
.executeUpdate();
...
// DELETE 벌크 연산
String qlString =
"DELETE from Product p " +
"WHERE p.price < :price";
int resultCount = em.createQuery(qlString)
.setParameter("price", 100)
.executeUpdate();
// INSERT 벌크 연산 (hibernate만 지원)
String qlString =
"INSERT into ProductTemp(id, name, price, stockAmount) " +
"SELECT p.id, p.name, p.price, p.stockAmount FROM Product p " +
"WHERE p.price < :price";
int resultCount = em.createQuery(qlString)
.setParameter("price", 100)
.executeUpdate();
벌크 연산의 주의점
- 벌크 연산시엔 영속성 컨텍스트 무시하고 바로 DB에 쿼리함
- ∴ 영속성 컨텍스트에 있는 값과 DB 값 간의 차이 발생할 수 있으므로 주의
- 이를 해결할 수 있는 방법은 다음과 같음
- em.refresh() 사용
- 벌크 연산 수행 직후 해당 연산 영향 받은 엔티티 사용해야 하면
em.refresh()호출해서 다시 조회
- 벌크 연산 수행 직후 해당 연산 영향 받은 엔티티 사용해야 하면
- 벌크 연산 먼저 실행
- 벌크 연산부터 실행 후 나머지 진행하면 됨
- 이 방법은 JPA, JDBC 같이 사용할 때도 유용함
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
- 벌크 연산 수행 직후 바로 영속성 컨텍스트 초기화 시켜서 남아있는 엔티티 제거하면 이후 사용할 때 다시 조회하기 때문에 차이 없앨 수 있음
- em.refresh() 사용
10.6.2 영속성 컨텍스트와 JPQL
쿼리 후 영속 상태인 것과 아닌 것
- JPQL로 엔티티 조회시
- 엔티티 => 영속성 컨텍스트에서 관리
- 엔티티 X(임베디드 타입, 단순 필드 조회 등) => 영속성 컨텍스트에서 관리 안함
- ∴ 엔티티 아닌거 조회하면 변경해도 수정 안됨
JPQL로 조회한 엔티티와 영속성 컨텍스트
- 영속성 컨텍스트에 이미 존재하는 엔티티를 JPQL로 다시 조회하는 경우 => 조회 결과 버리고 영속성 컨텍스트에 있던 기존 엔티티를 반환
- JPQL을 사용해서 조회 요청
- JPQL -> SQL로 변환되어 DB 조회
- 조회한 결과와 영속성 컨텍스트 비교(식별자 값을 기준으로 함)
- 이미 존재하는 엔티티인 경우 => 버리고 기존 엔티티를 반환
- 없으면 => 영속성 컨텍스트에 추가하고 반환
- 기존 엔티티 대신 새로 조회한 엔티티로 대체하지 않는 이유
- 영속성 컨텍스트에서 수정 중인 데이터가 사라질 수 있음
find() vs JPQL
em.find메소드는 엔티티를 영속성 컨텍스트에서 먼저 찾고 없으면 DB 조회- JPQL은 항상 DB에서 SQL 실행해서 결과를 조회
- 조회 후 영속성 컨텍스트랑 비교해서 영속 상태 유지되긴 함
10.6.3 JPQL과 플러시 모드
쿼리와 플러시 모드
- 영속성 컨텍스트에서 엔티티 수정 후 JPQL로 조회하는 경우 플러시 모드에 따라 의도치 않은 결과 얻을 수 있음
- 플러시 모드 AUTO인 경우
- JPQL 실행 직전에 영속성 컨텍스트가 플러시 돼서 수정된 결과를 조회 => 문제 없음
- 플러시 모드 COMMIT인 경우
- 쿼리시에는 플러시 하지 않으므로 방금 수정한 데이터가 조회되지 않음 => 의도치 않은 결과
- ∴ 직접
em.flush()호출하거나 아래와 같이 Query 객체에 flush mode 설정해줘야 함em.createQuery(...).setFlushMode(FlushModeType.AUTO).getSingleResult();- 이렇게 쿼리에 직접 설정하면 entity manager 에서 설정한 것보다 우선시 됨
- 플러시 모드 AUTO인 경우
플러시 모드와 최적화
- 데이터 무결성 깨질 위험 감수하고 flush mode를 COMMIT 으로 쓰는 경우
- 플러시가 너무 자주 일어나는 상황
- 매번 플러시 될 경우 성능 하락 생길 수 있음
- 이런 경우에 쿼리시 발생하는 플러시 횟수를 줄여서 성능 최적화
- JPA 사용하지 않고 JDBC 직접 사용해서 SQL 실행하는 경우
- JDBC로 쿼리 직접 실행 시 JPA는 JDBC가 실행한 쿼리 인식 못함
- ∴ 별도의 JDBC 호출은 플러시 모드 AUTO 설정해도 플러시 안됨
- 이런 경우엔 쿼리 실행 전
em.flush()호출해서 동기화 하는게 안전
- 플러시가 너무 자주 일어나는 상황
Subscribe via RSS
{kind=link}