[자바 ORM 표준 JPA 프로그래밍] 15장. 고급 주제와 성능 최적화
by Jo
15장. 고급 주제와 성능 최적화
15.1 예외 처리
15.1.1 JPA 표준 예외 정리
RuntimeException- ㄴ
javax.persistence.PersistenceException- ㄴ JPA 표준 예외
- 트랜잭션 롤백을 표시하는 예외
- 심각한 예외, 복구 X
- 트랜잭션 강제 커밋해도 안먹히고
javax.persistence.RollbackException발생
- 트랜잭션 롤백을 표시하지 않는 예외
- 심각하지 않은 예외
- 개발자가 커밋, 롤백 여부 판단해서 선택
- 트랜잭션 롤백을 표시하는 예외
- ㄴ JPA 표준 예외
- ㄴ
| 트랜잭션 롤백을 표시하는 예외 | 설명 |
|---|---|
| javax.persistence.EntityExistsException | EntityManager.persist(…) 호출 시 이미 같은 엔티티 있는 경우 |
| javax.persistence.EntityNotFoundException | EntityManager.getReference(…) 호출했는데 실제 사용 시 엔티티가 존재하지 않으면 발생 refresh(…), lock(…) 에서도 발생함 |
| javax.persistence.OptimisticLockException | 낙관적 락 충돌 시 발생 |
| javax.persistence.PessimisticLockException | 비관적 락 충돌 시 발생 |
| javax.persistence.RollbackException | EntityTranscation.commit() 실패 시 발생 롤백 표시되어 있는 트랜잭션 커밋 시에도 발생함 |
| javax.persistence.TranscationRequiredException | 트랜잭션 필요할 때 없으면 발생 트랜잭션 없이 엔티티 변경 시 주로 발생함 |
| 트랜잭션 롤백을 표시하지 않는 예외 | 설명 |
|---|---|
| javax.persistence.NoResultException | Query.getSingleResult() 호출 시 결과 하나도 없으면 발생 |
| javax.persistence.NonUniqueResultException | Query.getSingleResult() 호출 시 결과 둘 이상이면 발생 |
| javax.persistence.LockTimeoutException | 비관적 락에서 시간 초과 시 발생 |
| javax.persistence.QueryTimeoutException | 쿼리 실행 시간 초과 시 발생 |
15.1.2 스프링 프레임워크의 JPA 예외 변환
- 서비스 레이어에서 데이터 엑세스 레이어 구현 기술에 의존하는건 좋은 설계 아님
- 예외도 마찬가지로 서비스 레이어에서 JPA 예외 직접 사용해 JPA 에 의존하게 되는건 좋지 않음
- 이를 해결하기 위해 스프링에선 데이터 엑세스 레이어에 대한 예외를 추상화해서 제공해주고 있음
| JPA 예외 | 스프링 변환 예외 |
|---|---|
| javax.persistence.PersistenceException | org.springframework.orm.jpa.JpaSystemException |
| javax.persistence.NoResultException | org.springframework.dao.EmptyResultDataAccessException |
| javax.persistence.NonUniqueResultException | org.springframework.dao.EmptyResultDataAccessException |
| javax.persistence.LockTimeoutException | org.springframework.dao.CannotAcquireLockException |
| javax.persistence.QueryTimeoutException | org.springframework.dao.QueryTimeoutException |
| javax.persistence.EntityExistsException | org.springframework.dao.DataIntegrityViolationException |
| javax.persistence.EntityNotFoundException | org.springframework.dao.JpaObjectRetrievalFailureException |
| javax.persistence.OptimisticLockException | org.springframework.dao.JpaOptimisticLockingFailureException |
| javax.persistence.PessimisticLockException | org.springframework.dao.PessimisticLockingFailureException |
| javax.persistence.TransactionRequiredException | org.springframework.dao.InvalidDataAccessApiUsageException |
| javax.persistence.RollbackException | org.springframework.dao.TRansactionSystemException |
| javax.persistence.IllegalStateException | org.springframework.dao.InvalidDataACcessApiUsageException |
| javax.persistence.IllegalArgumnentException | org.springframework.dao.InvalidDataAccessApiUsageException |
15.1.3 스프링 프레임워크에 JPA 예외 변환기 적용
PersistenceExceptionTranslationPostProcessor를 스프링 빈으로 등록하여 JPA 예외 -> 스프링 예외 변환 기능 사용 가능@Repository어노테이션 사용한 곳에 예외 변환 AOP 적용해서 JPA 예외를 스프링 프레임워크의 추상화한 예외로 변환해줌
<!-- xml로 설정 -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslactionPostProcessor" />
// JavaConfig으로 설정
@Bean
public PersistenceExceptionTranslationPostProcessor exceptionTranslation() {
return new PersistenceExceptionTranslationPostProcessor();
}
// 예외 변환 예제
@Repostiroy
public class NoResultExceptionTestRepository {
@PersistnceContext EntityManger em;
public Member findMember() {
// 조회된 member 없음
return em.createQuery("SELECT m FROM Member m", Member.class)
.getSingleResult();
}
}
getSingleResult()메소드 호출- 조회된 결과 없어서
javax.persistence.NoResultException발생 PersistenceExceptionTranslationPostProcessor에서 등록한 AOP 인터셉터가 동작해 해당 예외를org.springframework.dao.EmptyResultDatAcessExcetpion으로 변환해서 리턴
- 예외 변환하지 않고 그대로 반환하려면 throws 절에 그대로 반환할 JPA 예외나 JPA 예외의 부모 클래스를 직접 명시
public member findMember() throws javax.persistence.NoResultException { // NoResultException 은 변환하지 않고 리턴함
15.1.4 트랜잭션 롤백 시 주의사항
- 트랜잭션 롤백은 DB 반영사항만 롤백, 수정한 자바 객체는 원상태 복구 안해줌
- DB 데이터는 원래대로 돌아가도 엔티티 객체는 수정된 상태로 영속성 컨텍스트에 남음
- ∴ 새로운 영속성 컨텍스트 생성하거나
EntityManager.clear()호출해서 초기화한 다음 사용해야 함 - 스프링 프레임워크는 이런 문제 예방을 위해 영속성 컨텍스트 범위에 따라 다른 방법을 사용
- 트랜잭션당 영속성 컨텍스트 전략
- 문제 발생시 트랜잭션 AOP 종료 시점에 트랜잭션 롤백 되며 영속성 컨텍스트도 종료되어 문제 없음
- OSIV 처럼 영속성 컨텍스트 범위를 트랜잭션 범위보다 넒게 사용해 여러 트랜잭션이 하나의 영속성 컨텍스트 사용하는 경우
- 트랜잭션 롤백해서 영속성 컨텍스트 이상 발생해도 다른 트랜잭션이 해당 영속성 컨텍스트 그대로 사용하게 되는 문제 있음
- 스프링에서는 영속성 컨텍스트 범위를 트랜잭션 보다 넓게 설정하면 트랜잭션 롤백 시
EntityManager.clear()로 영속성 컨텍스트 초기화 시켜서 문제 예방함
- 트랜잭션당 영속성 컨텍스트 전략
15.2 엔티티 비교
- 애플리케이션 수준의 반복 가능한 읽기
- 1차 캐시의 가장 큰 장점
- 같은 영속성 컨텍스트에서 엔티티 조회 시 항상 같은 엔티티 인스턴스를 반환
15.2.1 영속성 컨텍스트가 같을 때 엔티티 비교
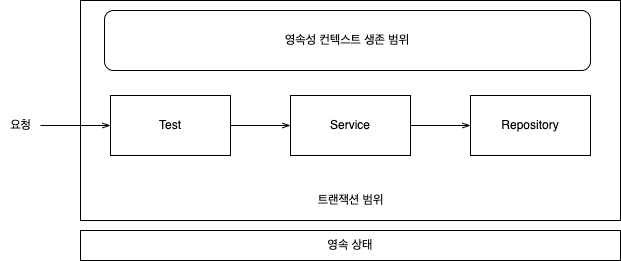
// 회원가입 테스트 케이스에서의 테스트와 트랜잭션 범위 예제
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:appConfig.xml")
@Transactional // 트랜잭션 안에서 테스트를 실행
public class MemberServiceTest {
@Autowired MemberService memberService;
@Autowired MemberRepsotiroy memberRepository;
@Test
public void joinTest() throws Exception {
// Given
Member member = new Member("kim");
// When
Long saveId = memberService.join(member);
// Then
Member findMember = memberRepository.findOne(saveId)
asertTrue(member == findMember); // 참조값 비교
}
}
...
@Transactional // 이 예제에서는 Test 클래스에서 Transaction 시작해서 그거 이어받아서 사용함
public class MemberService {
@Autowired MemberRepository memberRepository;
public Long join(Member member) {
...
memberRepository.save(member);
return member.getId();
}
}
...
@Repository
public class MemberRepository {
@PersistenceContext
EntityManager em;
public void save(Member member) {
em.persist(member);
}
public Member findOne(Long id) {
return em.find(Member.class, id);
}
}
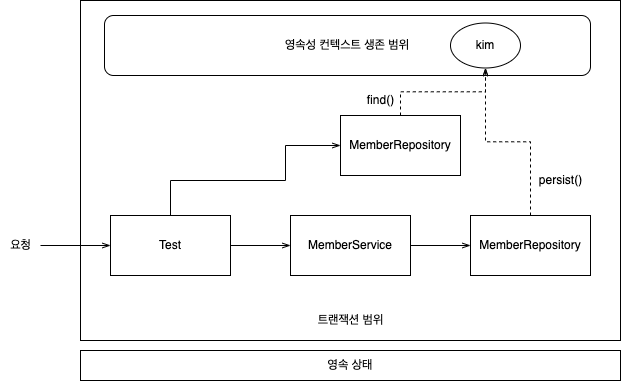
- 테스트 클래스에
@Transactional선언되어 있으면 트랜잭션 먼저 시작 후 테스트 메소드 실행되므로joinTest()메소드는 트랜잭션 범위의 안쪽, 해당 메소드 끝나면 트랜잭션 종료됨- 테스트 클래스에
@Transactional적용하면 테스트 끝날 때 트랜잭션 강제 롤백함
- 테스트 클래스에
- ∴
joinTest()에서 사용된 코드는 항상 같은 트랜잭션, 같은 영속성 컨텍스트에 접근- 위 예제에서 저장한 member와 레포지토리에서 조회해온 엔티티가 완전히 같은 인스턴스 => 같은 트랜잭션 범위 안이라 동일한 영속성 컨텍스트를 사용하기 때문
- 영속성 컨텍스트가 같으면 엔티티 비교시 다음 3가지 조건 모두 만족함
- 동일성 identical:
==비교가 같음 - 동등성 equinalent:
equals()비교가 같음 - DB 동등성:
@Id인 DB 식별자가 같음
- 동일성 identical:
15.2.2 영속성 컨텍스트가 다를 때 엔티티 비교
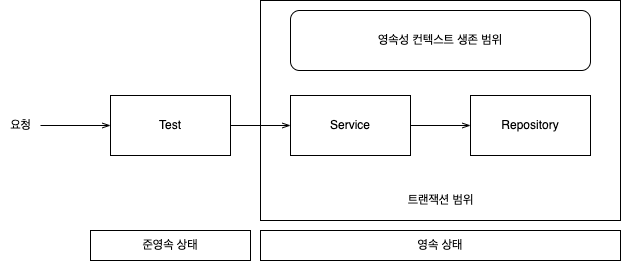
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:appConfig.xml")
// @Transcational 테스트에서 트랜잭션 사용 안함
public class MemberServiceTest {
@Autowired
MemberService memberService;
@Autowired
MemberRepsotiroy memberRepository;
@Test
public void joinTest() throws Exception {
// Given
Member member = new Member("kim");
// When
Long saveId = memberService.join(member);
// Then
Member findMember = memberRepository.findOne(saveId) // Transaction은 MemberRepository::findOne 종료되며 같이 끝났기 때문에 findMember 는 준영속 상태
asertTrue(member == findMember); // member 와 findMEmber 는 다른 주소값을 가진 인스턴스 => 테스트 실패
}
}
...
@Transactional // 서비스 클래스에서 트랜잭션이 시작됨
public class MemberService {
@Autowired MemberRepository memberRepository;
public Long join(Member member) {
...
memberRepository.save(member);
return member.getId();
}
}
...
@Repository
@Transactional // 이 예제에서는 Test 클래스에서 트랜잭션 시작 안하기 때문에 여기도 추가
public class MemberRepository {
@PersistenceContext
EntityManager em;
public void save(Member member) {
em.persist(member);
}
public Member findOne(Long id) {
return em.find(Member.class, id);
}
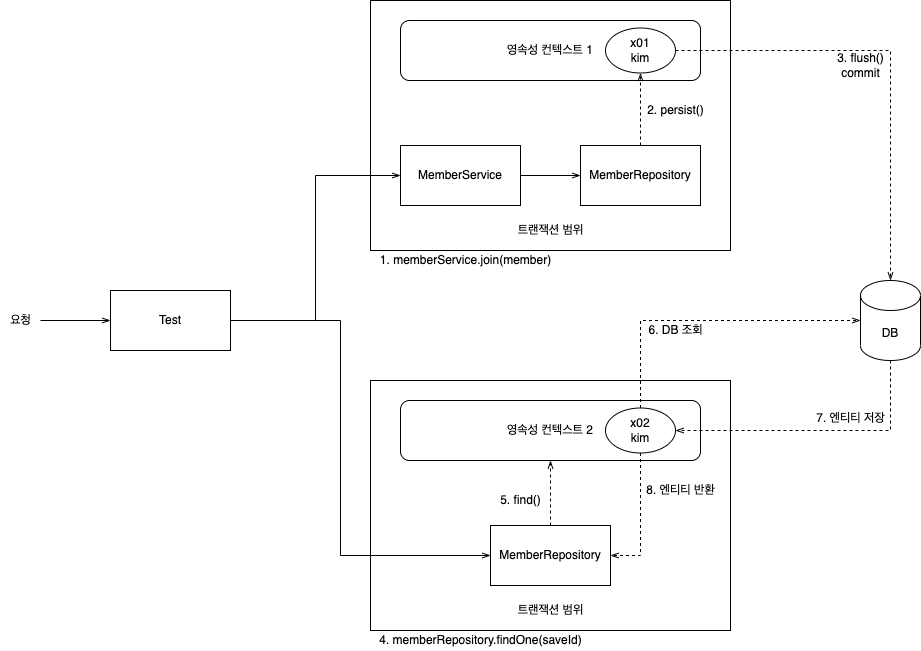
- Test 코드에서
memberService.join(member)호출, 회원가입 시도하면 서비스 레이어에서 트랜잭션 시작, 영속성 컨텍스트 1 생성됨 memberRepsitory에서em.persist()호출해서 member 엔티티 영속화- 서비스 레이어 끝날 때 트랜잭션 커밋되며 영속성 컨텍스트 플러시 되고 트랜잭션, 영속성 컨텍스트 종료. member 엔티티 인스턴스는 준영속 상태 됨
- 테스트 코드에서
memberRepository.findOne(saveId)호출해 저장한 엔티티 조회하면 레포지토리 레이어에서 새로운 트랜잭션 시작, 영속성 컨텍스트 2 생성됨 - 저장된 member 조회하지만 영속성 컨텍스트 2 에는 해당 member 없음
- DB 에서 해당 member 조회해 옴
- DB 에서 조회된 member 엔티티를 영속성 컨텍스트에 보관하고 반환
memberRepository.findOne()메소드 끝나며 트랜잭션 종료, 영속성 컨텍스트 2 종료
- member 와 findMember 는 다른 영속성 컨텍스트에서 관리되어 서로 다른 인스턴스
assertTrue(member == findMember)실패함
- 영속성 컨텍스트 다른 경우 엔티티 비교 결과는 아래와 같음
- 동일성 identical:
==비교 실패 - 동등성 equinalent:
equals()비교 만족. 대신equals()구현해야 함- 엔티티 비교를 위해
equals()구현시엔 비즈니스 키를 활용한 동등성 비교를 권장
- 엔티티 비교를 위해
- DB 동등성: @Id 인 DB 식별자 값 같음
- 동일성 identical:
15.3 프록시 심화 주제
15.3.1 영속성 컨텍스트와 프록시
- 영속성 컨텍스트는 자신이 관리하는 영속 엔티티의 동일성 보장
- 프록시로 조회한 엔티티의 경우에도 동일성을 보장함
- 프록시 먼저 조회 후 원본 엔티티 조회한 경우
- 이미 프록시로 조회한 엔티티에 대해 같은 엔티티 조회 요청 오면 원본이 아닌 처음 조회된 프록시를 반환
- ∴ 둘다 동일한 프록시 반환되어 동일성 보장
- 원본 엔티티 먼저 조회 후 프록시 조회한 경우
- 원본 엔티티를 이미 DB에서 조회해서 영속성 컨텍스트에서 관리중이므로 프록시로 요청해도 원본 엔티티를 반환
- ∴ 둘다 동일한 원본 엔티티 반환되어 동일성 보장
- 프록시 먼저 조회 후 원본 엔티티 조회한 경우
15.3.2 프록시 타입 비교
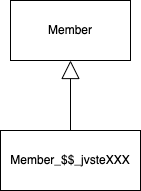
- 프록시는 원본 엔티티 상속받아 만들어지므로 타입 비교시
==대신instanceof사용해야 함 - 프록시와 원본 엔티티를
==로 비교하게 되면 부모 클래스와 자식 클래스를 비교한 것이 됨 => 결과는 false - ∴
instanceof를 통해 비교해야 함
15.3.3 프록시 동등성 비교
- 엔티티 동등성 비교 시 비즈니스 키 이용해
equals()메소드 오버라이딩 하여 비교하면 됨 - IDE나 외부 라이브러리 사용해서 구현한
equals()메소드를 엔티티 비교에 사용해도 원본 엔티티면 문제 없음- 프록시인 경우엔 문제 발생할 수 있음
@Entity
public class Member {
@Id
private String id;
private String name;
...
public String getName() { return name; }
public void setName(String name) { this.name = name; }
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null) return false;
if (this.getClass() != obj.getClass()) return false; // 문제점 1
Member member = (Member) obj;
if (name != null ? !name.equals(member.name) : member.name != null) return false; // 문제점 2
return true;
}
@Override
public int hashCode() {
return name != null ? name.hashCode() : 0;
}
}
...
@TEst
public void proxyEquivalnceTest() {
Member saveMember = new Member("member1", "memberA");
em.persiste(saveMember);
em.flush();
em.clear();
Member newMEmber = new Member("member1", "memberA");
Member refMember = em.getReference(Member.class, "memberA");
Assert.assertTrue(newMember.equals(refMember)); // 실패
}

- 위 예제에서
Assert.assertTrue(newMember.equals(refMember));가 실패하는 이유는 다음과 같음
문제점 1: 타입 비교
if (this.getClass() != obj.getClass()) return false;
- 프록시는 원본을 상속받은 자식 타입이므로 프록시 타입 비교시
==가 아닌instanceof를 사용해야 함
문제점 2: 프록시 멤버 변수 접근
Member member = (Member) obj;
if (name != null ? !name.equals(member.name) : member.name != null) return false;
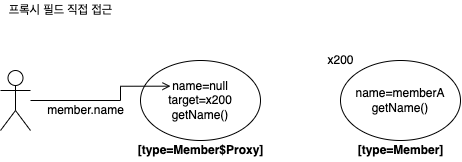
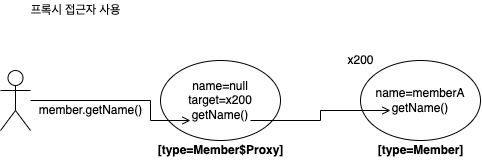
- 프록시는 실제 데이터를 가지고 있지 않음
- 따라서 프록시의 멤버 변수에 직접 접근하면 아무 값도 조회할 수 없음
- 접근자를 사용해 멤버 변수에 접근해야 원본 엔티티 조회해와서 실제 값에 접근할 수 있음
문제 해결한 equals() 메소드 예제
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Member)) return false; // 프록시의 타입 비교는 == 대신 instanceof 사용
Member member = (Member) obj;
if (name != null ? !name.equals(member.getName()) : member.getName() != null) return false; // 프록시의 멤버 변수에 직접 접근하지 말고 getter 메소드 사용
return true;
}
15.3.4 상속관계와 프록시
- 프록시를 부모 타입으로 조회할 경우 부모 타입을 기반으로 프록시가 생성되어 문제 발생
instanceof연산 사용 불가- 하위 타입으로 다운 캐스팅 불가
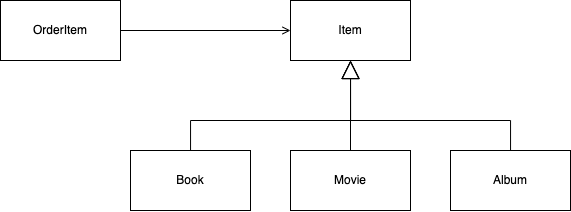
@Test
public void proxyQueryByParentType() {
// test 데이터 준비
Book saveBook = new Book();
saveBook.setName("jpabook");
saveBook.setAuthor("kim");
em.persist(saveBook);
em.flush();
em.clear();
// test 시작
Item proxyItem = em.getReference(Item.class, saveBook.getId());
System.out.println("proxyItem = " + proxyItem.getClass()); // proxyItem = class jpabook.proxy.advanced.item.Item_$$_jvstXXX
if (proxyItem instanceof book) {
System.out.println("proxyItem instance of book");
Book book = (Book) proxyItem;
System.out.println("author = " + book.getAuthor());
}
// assert
Assert.asesertFalse(proxyItem.getClass() == Book.class);
Assert.assertFalse(proxyItem instanceof Book); // false
Assert.assertTrue(proxyItem instanceof Item); // true
}
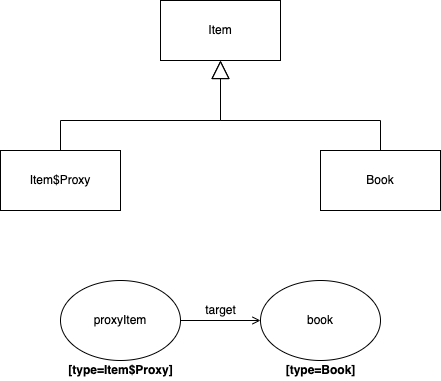
- 위 예제의 경우
em.getRefernce(Item.class, saveBook.getId())로 조회한 결과과Item을 상속받은 프록시 클래스임 - 프록시의 원본은
Book엔티티이지만 프록시 자체는Item을 상속받아Book클래스와 관련이 없기 때문에proxyItem instanceof Book의 결과가 false 가 됨 - 따라서 다운 캐스팅을 해줘도
classCastException예외가 발생함
JPQL로 대상 직접 조회
- 가장 간단한 해결책은 처음부터 자식 타입을 직접 조회해서 필요한 연산을 수행하는 것
- 대신 이 방법 사용하면 다형성 활용 못함
Book jpqlBook = em
.createQuery("SELECT b FROM Book b WHERE b.id=:bookId", Book.class)
.setParameter("bookId", item.getId())
.getSingleResult();
프록시 벗기기
@Test
public void proxyQueryByParentType() {
...
Item item = orderItem.getItem();
Item unProxyItem = unProxy(item);
if (unProxyItem instanceof Book) {
System.out.println("proxyItem insatnceof Book");
Book book = (Book) unProxyItem;
System.out.println("author = " + book.getAuthor());
}
Assert.assertTrue(item != unProxyItem); // true
}
// 프록시에서 원본 엔티티 찾는 기능 사용 예제
public static <T> T unProxy(Object entity) {
if (entity instanceof HibernateProxy) {
entity = ((HibernateProxy) entity)
.getHibernateLazyInitializer()
.getImplementation();
}
return (T) entity;
}
- 위 예제와 같이 하이버네이트가 제공하는 기능 사용하면 프록시에서 원본 엔티티 가져와 프록시를 벗기고 사용할 수 있음
((HibernateProxy) entity).getHibernateLazyInitializer().getImplementation();
- 대신 이렇게 할 경우 프록시에서 원본 엔티티 꺼내서 사용하기 때문에 프록시와 원본 엔티티 동일성 비교가 실패함
item == unProxyItem // false- 원래 영속성 컨텍스트는 한번 프록시로 노출한 엔티티는 계속 프록시로 노출해서 영속 엔티티의 동일성을 보장하지만 프록시 벗기면 그게 안됨
- 원본 엔티티 값을 직접 변경해도 변경 감지 기능은 동작함
기능을 위한 별도의 인터페이스 제공
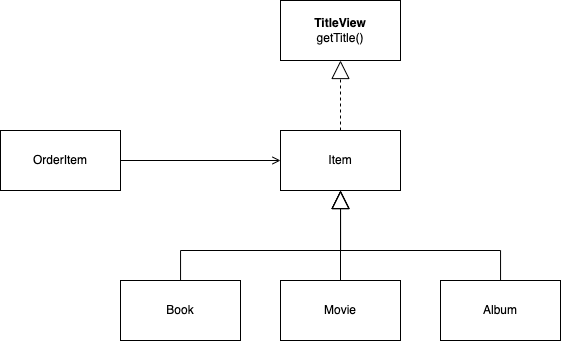
public interface TitleView {
String getTitle();
}
...
@Entity
@Inheritance(startegry = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
public abstract class Item implements TitleView {
@Id
@GeneratedValue
@Column(name = "item_id")
private Long id;
private String name;
private int price;
private int stockQuantity;
// Getter, Setter
}
...
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
// Getter, Setter
@Override
public String getTitle() {
return "[title: " + getName() + "director: " + director + "actor: " + actor + "]";
}
}
...
@Entity
public class OrderItem {
@Id
@GenearatedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "item_id")
private Item item;
...
public void printItem() {
System.out.pritnln("TITLE=" + item.getTitle());
}
}
- 위 예제처럼 인터페이스를 제공하고 각 클래스에서 기능을 구현하여 사용하는 것이 다형성을 활요하는 좋은 방법
- 또한 클라이언트 입장에서 대상 객체가 프록시인지 아닌지 고려하지 않아도 됨
- 이 방법 사용시엔 프록시의 특징 때문에 프록시의 대상이 되는 타입에 인터페이스 적용해야 함
- 위 예시의 경우
Item이 인터페이스 적용 대상
- 위 예시의 경우
비지터 패턴 사용

- 비지터 패턴은
Visitor와Visitor를 받아들이는 대상 클래스로 구성됨 - 예제의 경우
Item이accept(visitor)메소드로Visitor받아들임Item은Visitor받아들이기만 하고 실제 로직은Visitor가 처리
Visitor 정의과 구현
// Visitor 인터페이스
public interface Visitor {
void visit(Book book);
void visit(Album album);
void visit(Movie movie);
}
// Visitor 구현
public class PrintVisitor implemnts Visitor {
@Override
public void visit(Book book) {
// 넘어오는 book 은 proxy 가 아닌 원본 엔티티
System.out.println("book.class = " + book.getClass());
System.out.println("[PrintVisitor] [title: " + book.getName() + "author: " + book.getAuthor() + "]");
}
@Override
public void visit(Album album) { ... }
@Override
public void visit(Movie movie) { ... }
}
...
public class TitleVisitor implemnts Visitor {
private String title;
public String getTitle() {
return title;
}
@Override
public void visit(Book book) {
title = "[title: " + book.getName() + "author: " + book.getAuthor() + "]";
}
@Override
public void visit(Album album) { ... }
@Override
public void visit(Movie movie) { ... }
}
Visitor클래스에 모든 대상 클래스 받아들이도록visit()메소드 작성Visitor의 구현 클래스로 대상 클래스 내용 출력하는PrintVisitor, 대상 클래스 제목 반환하는TitleVisitor작성
대상 클래스 작성
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
public abstract class Item {
@Id
@GeneratedValue
@Column(name = "item_id")
private Long id;
private String name;
...
public abstract void accept(Visitor visitor);
}
...
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
private String isbn;
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
// Getter, Setter
...
}
...
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
...
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
...
@Entity
@DiscriminatorValue("A")
public class Album extends Item {
...
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
- 각 자식 클래스에 부모에서 정의한
accept(visitor)메소드 구현- 파라미터로 넘어온
Visitor의visit(this)메소드 호출하며 자신을 파라미터로 넘기는게 전부임 - 실제 로직 처리는
visitor에 위임
- 파라미터로 넘어온
비지터 패턴 실행
@Test
public void visitorPattern() {
...
OrderItem orderItem = em.find(OrderItem.class, orderItemId);
Item item = orderItem.getItem();
// PrintVisitor
item.accept(new PrintVisitor());
}

item.accept()aㅔ소드 호출하며 파라미터로PrintVisitor전달item은 프록시이므로ProxyItem이 먼저accept()메소드 받고 원본 엔티티Book의 ```accept()`` 실행- 원본 엔티티는
visitor.visit(this)실행해서 자신을visitor에 파라미터로 전달 visitor가PrintVisitor타입이므로PrintVisitor::visit(Book book)메소드가 실행PrintVisitor::visit(Book book)으로 넘어오는 엔티티는 프록시가 아닌 원본 엔티티
비지터 패턴과 확장성
- 비지터 패턴은 새로운 기능 필요할 때
Visitor만 추가하면 됨 - 따라서 기존 코드 구조 변경 없이 기능 추가할 수 있음
비지터 패턴 정리
- 장점
- 프록시 걱정 없이 안전하게 원본 엔티티 접근 가능
- instanceof, 타입캐스팅 없이 코드 구현 가능
- 알고리즘과 객체 구조 분리하여 구조 수정 없이 새로운 동작 추가 가능
- 단점
- 복잡도가 높으며 더블 디스패치 사용하여 난해할 수 있음
- 객체 구조 변경시 모든 Visitor 수정해야 함
15.4 성능 최적화
15.4.1 N+1 문제
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
...
}
...
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue
private Long id;
@ManyToOne
private Member member;
...
}
- Member 와 Order 는 1:N, N:1 양방향 연관관계
- Member 가 참조하는
Member.orders를 즉시 로딩으로 설정
즉시 로딩과 N+1
- 특정 Member 를
em.find()로 조회 시 즉시 로딩 설정한 order 도 함께 조회됨- 이 때는 join 사용해서 Member, Order 를 함께 조회
- JPQL로 조회할 경우엔 즉시 로딩, 지연 로딩 설정 여부 상관안함
- Member와 Order를 join으로 함께 조회하지 않고 Member 만 조회함
- 이후 JPA가 Order 도 즉시 로딩 하기 위해 추가적으로 조회 쿼리 날림
- 이 때 처음 실행한 SQL 의 결과 수만큼 추가로 SQL 실행됨 => N+1 문제
지연 로딩과 N+1
// 지연 로딩 설정
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "memgber", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<Order>();
...
}
...
// 지연 로딩 설정해도 N+1 문제 발생하는 예시
for (Member member: members) {
// 지연 로딩 초기화
System.out.println("member = " + member.getOrders().size());
}
- 지연 로딩시에도 문제 발생할 수 있음
- 위 예제처럼 모든 Member 에 대해 연관된 Order 컬렉션 사용시 Order 컬렉션 초기화하는 수만큼 Order 조회 쿼리가 실행될 수 있음
- Member 수만큼 Order 조회 쿼리 수행되므로 N+1 문제
페치 조인 사용
- N+1 문제의 가장 일반적 해결법은 fetch join 사용
- fetch 조인은 SQL 조인 사용해서 연관된 엔티티 한번에 조회하므로 N+1 문제 발생 안함
하이버네이트 @BatchSize
- 하이버네이트의
org.hibernate.annotations.BatchSize어노테이션 사용하면 연관된 엔티티 조회 시 지정한 size 만큼 SQL 의 IN 절 사용해서 조회- Member 10명일 때 size=5 지정하면 2번의 쿼리만 추가 실행
@Entity
public class Member {
...
@BatchSize(size = 5)
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
...
}
- 즉시 로딩으로 설정하면 조회 시점에 N 개 데이터 모두 조회해야 해서 쿼리가 N/size 번 수행
- 지연 로딩으로 설정하면 지연 로딩된 엔티티 최초 사용 시점에 쿼리 한번 수행해서 size 개 데이터 미리 로딩, 이후 size+1 번째 데이터 사용시 추가로 조회
SELECT * FROM orders WHERE member_id IN (?, ?, ?, ?, ?) // @BatchSize(size=5) 설정시 수행되는 쿼리
hibernate.default_batch_fetch_size속성 사용하여@BatchSize글로벌 적용 가능함
<property name="hibernate.default_batch_fetch_size" value="5" />
하이버네이트 @Fetch(FetchMode.SUBSELECT)
- 하이버네이트의
org.hibernate.annotations.Fetch어노테이션에 FetchMode 를 SUBSELECT 로 사용하면 연관 데이터 조회시 서브 쿼리 사용해서 N+1 문제 해결
@Entity
public class Member {
...
@Fetch(FetchMode.SUBSELECT)
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
}
// @Fetch(FetchMode.SUBSELECT) 사용하는 JPQL 예제
SELECT m
FROM Member m
WHERE m.id > 10
- 위와 같은 JPQL 로 Member 조회하면 지연 로딩된 엔티티 사용하는 시점에 다음과 같은 SQL 실행됨
# SQL
SELECT o FROM orders o
WHERE o.member_id IN (
SELECT m.id
FROM member m
WHERE m.id > 10
)
N+1 정리
- 즉시 로딩 말고 지연 로딩만 사용하는 것 권장
- 즉시 로딩은 N+1 문제 뿐만 아니라 필요없는 엔티티도 로딩해야 하는 상황 자주 발생
- 이러한 이유로 즉시 로딩은 성능 최적화가 어려움
- 따라서 모두 지연 로딩 설정 후 성능 최적화 필수인 곳에 JPQL 페치 조인 사용하는 게 좋음
- JPA 글로벌 페치 전략 기본값
@OneToOne,@ManyToOne: 즉시 로딩@OneToMany,@ManyToMany: 지연 로딩- 따라서 기본값이 즉시 로딩인
@OneToOne,@ManyToOne은 지연 로딩 설정 해줘서 사용하는게 좋다
15.4.2 읽기 전용 쿼리의 성능 최적화
- 영속성 컨텍스트는 변경 감지를 위해 스냅샷 인스턴스를 보관하기 때문에 더 많은 메모리를 사용함
- 만약 수정이나 여러번의 조회가 필요 없이 딱 한 번만 조회해서 사용하면 되는 경우 영속성 컨텍스트에 의해 관리되지 않는 읽기 전용으로 조회하면 메모리 사용량을 최적화 할 수 있음
// 최적화 전 JPQL
SELECT o FROM Order o
스칼라 타입으로 조회
// 스칼라 타입으로 조회 JPQL
SELECT o.id, o.name, o.price FROM Order p
- 엔티티가 아닌 스칼라 타입으로 모든 필드를 조회하는 방법
- 스칼라 타입은 영속성 컨텍스트가 결과 관리 안함
읽기 전용 쿼리 힌트 사용
// 읽기 전용 쿼리 힌트 사용 예제
TypedQuery<Order> query = em.createQuery("SELECT o FROM Order o", Order.class);
query.setHint("org.hibernate.readOnly", true);
- 하이버네이트 전용 힌트
org.hibernate.readOnly사용하여 읽기 전용으로 조회할 수 있음 - 영속성 컨텍스트는 해당 엔티티에 대해 스냅샷 보관하지 않음
- 따라서 메모리 사용량 최적화 되고 대신 스냅샷 없어서 엔티티 수정해도 DB 반영 안됨
읽기 전용 트랜잭션 사용
// 트랜잭션 읽기 전용 모드 설정
@Transactional(readOnly = true)
public List<Order> getOrders() { ... }
- 트랜잭션에
readOnly = true옵션 주면 스프링 프레임워크가 하이버네이트 세션의 flush mode 를 MANUAL 로 설정함- 강제로 플러시 호출 안하면 플러시 안일어남
- 따라서 트랜잭션 커밋해도 영속성 컨텍스트 플러시 되지 않아 엔티티 등록, 수정, 삭제 동작하지 않음
- 덕분에 플러시 시 발생하는 스냅샷 비교 등의 무거운 로직 수행되지 않아 성능 향상됨
트랜잭션 밖에서 읽기
// 트랜잭션 밖에서 읽기 설정
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public List<Order> getOrders() { ... }
- 트랜잭션 없이 엔티티를 조회하는 방법
- 데이터 변경하려면 트랜잭션 필수이기 때문에 조회가 목적일 때만 사용해야 함
- 이렇게 조회하면 트랜잭션 사용하지 않아 flush 도 일어나지 않으므로 조회 성능이 향상됨
정리
- 읽기 전용 데이터 조회시
- 메모리 최적화 하려면
- 스칼라 타입으로 조회
- 하이버네이트의 읽기 전용 쿼리 힌트 사용
- flush 호출을 막아 속도 최적화 하려면
- 읽기 전용 트랜잭션 사용 (스프링에서는 이게 더 편함)
- 트랜잭션 밖에서 읽기
- 메모리 최적화 하려면
- 따라서 아래 예제와 같이 읽기 전용 트랜잭션(or 트랜잭션 밖에서 읽기) 랑 읽기 전용 쿼리 힌트(or 스칼라 타입으로 조회) 동시에 사용하는게 가장 효과적임
@Transactional(readOnly = true) // 읽기 전용 트랜잭션: flush 막아서 성능 향상
public List<DataEntity> findDatas() {
return em.createQuery("SELECT d FROM DataEntity d", DataEntity.class)
.setHint("org.hibernate.readOnly", true) // 읽기 전용 엔티티 사용: 읽기 전용으로 조회해서 메모리 절약
.getResultList();
}
15.4.3 배치 처리
- 수많은 데이터 배치 처리해야하는 상황에서 일반적 방식으로 엔티티 계속 조회시 영속성 컨텍스트에 엔티티 과도하게 쌓여 메모리 부족 에러 남
- ∴ 이런 배치 처리는 적절한 단위로 영속성 컨텍스트 초기화해야 하며, 2차 캐시 사용중이면 2차 캐시에 엔티티 보관하지 않도록 주의
JPA 등록 배치
- 영속성 컨텍스트에 엔티티가 계속 쌓이지 않도록 일정 단위마다 영속성 컨텍스트의 엔티티를 DB 에 플러시 하고 영속성 컨텍스트 초기화 해야함
for (int i = 0; i < 100000; i++) {
Product product = new Product("item" + i, 10000);
em.persist(product);
// 100건 마다 플러시하고 영속성 컨텍스트 초기화
if (i % 100 == 0) {
em.flush();
em.clear();
}
}
JPA 수정 배치
- 수정 배치 처리시에는 다량의 데이터를 조회해서 수정해야 하는데 이 때 수많은 데이터를 한 번에 메모리에 올려둘 수 없어 다음 두 가지 방법을 주로 사용
- 페이징 처리: DB 페이징 기능을 사용
- 커서 CURSOR: DB 가 지원하는 커서 기능을 사용
- JPA 는 JDBC CURSOR 지원하지 않으므로 하이버네이트 Session 사용해야 함
JPA 페이징 배치 처리
int pageSize = 100;
for (int i = 0; i < 10; i++) {
List<Product> resultList = em.createQuery("SELECT p FROM Product p", Product.class)
.setFirstResult(i * pageSize)
.setMaxResults(pageSize) // 한 번에 100 건씩 페이징 쿼리로 조회하고 로직 수행 후 flsuh, clear
.getResultList();
// 비즈니스 로직 실행
for (Product prodcut: resultList) {
product.setPrice(product.getPrice() + 100);
}
em.flush();
em.clear();
}
- 페이징 조회해서 페이지 단위마다 로직 수행하고 플러시, 초기화
하이버네이트 scroll 사용
EntityTransaction tx = em.getTransaction();
Session session = em.unwrap(Session.class); // hibernate 세션 구함
tx.begin();
ScrollableResults scroll = session.createQuery("SELECT p FROM Product p")
.setCacheMode(CacheMode.IGNORE) // 2차 캐시 기능 off
.scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while (scroll.next()) {
Product p = (Product) scroll.get(0);
p.setPrice(p.getPrice() + 100);
count++;
if (count % 100 == 0) {
session.flush();
}
}
tx.commit();
session.close();
- 하이버네이트는 Scroll 이라는 이름으로 JDBC 커서 지원
- scroll은 하이버네이트 전용 기능이므로
em.unwrap()으로 하이버네이트 세션 먼저 구함 - 쿼리 조회하면서
scroll()메소드로ScrollableResults객체 반환받음 ScrollableResults객체의next()메소드 호출하면 엔티티 하나씩 조회 가능
하이버네이트 무상태 세션 사용
- 영속성 컨텍스트를 만들지 않고 2차 캐시도 사용하지 않는 세션
- 일반 하이버네이트 세션과 거의 비슷하지만 영속성 컨텍스트가 없음
- 영속성 컨텍스트를 플러시하거나 초기화하지 않아도 됨
- 대신 엔티티 수정시 무상태 세션이 제공하는
update()메소드 직접 호출해야 함
SessionFactory sessionFactory = entityManagerFactory.unwrap(SessionFactory.class);
StatelessSession session = sessionFactory.openStatelessSession();
Transaction tx = session.beginTransaction();
ScrollableResults scroll = sesssion.createQuery("SELECT p FROM Product p").scroll();
while (scroll.next()) {
Product p = (Product) scroll.get(0);
p.setPrice(p.getPrice() + 100);
session.update(p) // 값 수정하기 위해 StatelessSession 의 update 메소드 호출
}
tx.commit();
session.close();
15.4.4 SQL 쿼리 힌트 사용
- JPA는 DB SQL 힌트(JPA 가 아닌 DB 벤더에게 제공하는 힌트) 기능 제공하지 않아 하이버네이트 직접 사용해야 함
- SQL 힌트는 하이버네이트 쿼리의
addQueryHint()메소드 사용 - 하이버네이트 4.3.10 까지는 오라클 방언만 힌트 적용됨
- 다른 DB 에서 사용하려면 각 방언에서
org.hibernate.dialect.Dialect에 있는 다음 메소드 오버라이딩해서 기능 구현해야 함public String getQueryHintString(String query, List<String> hints) { return query; }
- 다른 DB 에서 사용하려면 각 방언에서
// SQL 쿼리 힌트 사용 예제
Session session = em.unwrap(Session.class) // 하이버네이트 직접 사용
List<MembeR> list = ession.createQuery("SELECT m FROM Member m")
.addQueryHint("FULL (member)") // SQL hint 추가
.list();
# 실행된 SQL
SELECT
/*+ FULL (member) */ m.id, m.name
FROM
member m
15.4.5 트랜잭션을 지원하는 쓰기 지연과 성능 최적화
트랜잭션을 지원하는 쓰기 지연과 JDBC 배치
// 최적화 전 예시
insert(member1); // INSERT INTO ...
insert(member2); // INSERT INTO ...
insert(member3); // INSERT INTO ...
...
commit();
- 네트워크 호출 한 번은 단순 메소드 수만 번 호출보다 비용 큼
- 위 예시처럼 여러 번에 걸쳐 DB 와 통신하면 비용 많이 듬
- 따라서 이걸 최적화 하려면 쿼리 모아서 한 번에 DB 에 보내면 됨
- JDBC 의 SQL 배치 기능 사용하면 SQL 모아서 DB에 보낼 수 있음
- 다만 이 기능 사용하려면 코드 상당수 수정 필요하고 복잡하며 지저분함
- 따라서 보통 수백, 수천 건 이상 데이터 변경하는 경우 사용
- JPA 는 플러시 기능이 있어 SQL 배치 기능 효과적으로 사용 가능
- SQL 배치 최적화 전략은 구현체 마다 차이가 있으며 하이버네이트는 다음과 같이 설정
<property name="hibernate.jdbc.batch_size" value="50"/>- 이렇게 설정하면 데이터 등록, 수정, 삭제 시 SQL 배치 기능을 사용함
- 위 예시의 경우 value=50 으로 설정하여 최대 50건씩 모아서 SQL 배치 실행
// SQL 배치 적용 예시
em.persist(new Member()); // 1
em.persist(new Member()); // 2
em.persist(new Member()); // 3
em.persist(new Member()); // 4
em.persist(new Child()); // 5, 다른 연산.
em.persist(new Member()); // 6
em.persist(new Member()); // 7
- SQL 배치는 동일한 SQL 일 때만 유효함
- 중간에 다른 처리 들어가면 SQL 배치 다시 시작함
- 위 예시 같은 경우 5 번이 다른 처리이기 때문에 1, 2, 3, 4 묶어서 실행 후 5번 실행하고 나머지 6, 7 번 묶어서 실행함
IDENTITY 식별자 생성 전략은 엔티티 DB 저장해야 식별자 구할 수 있어서 em.persist() 호출 즉시 INSER SQL 이 DB 에 전달됨
∴ 쓰기 지연 활용한 성능 최적화 불가능함
트랜잭션을 지원하는 쓰기 지연과 애플리케이션 확장성
update(memberA); // UPDATE SQL A
logicA(); // UPDATE SQL ...
logicB(); // INSER SQL ...
commit();
- 트랜잭션을 지원하는 쓰기 지연의 진짜 장점은 DB 테이블 row에 lock 걸리는 시간을 최소화 한다는 것
- 트랜잭션을 커밋해서 영속성 컨텍스트 플러시하기 전까지는 DB에 데이터 등록, 수정, 삭제 안함
- ∴ 커밋 직전까지 DB row 에 lock 안 검
- JPA 사용하지 않고 직접 SQL 다루면 commit 할 때까지 lock 유지됨
- 위 예제의 경우
update(memberA)에서부터 lock 걸려서commit()까지 유지
- 위 예제의 경우
- JPA 사용하면 커밋 해야 플러시 호출하고 DB에 쿼리 보내지기 때문에 DB 락 걸리는 시간이 최소화 됨
- 위 예제의 경우
commit()할 때 UPDATE, INSERT 쿼리 DB 로 보내져서 lock 걸고 수행 후 커밋하고 바로 풀림
- 위 예제의 경우
Subscribe via RSS
{kind=link}