[자바 ORM 표준 JPA 프로그래밍] 16장. 트랜잭션과 락, 2차 캐시
by Jo
16장. 트랜잭션과 락, 2차 캐시
16.1 트랜잭션과 락
16.1.1 트랜잭션과 격리 수준
- 트랜잭션은 ACID를 보장해야 함
- 원자성 (Atomicity): 트랜잭션 내에서 실행한 작업들은 하나의 작업인것 처럼 모두 성공하거나 모두 실패해야 함
- 일관성 (Consistencey): 모든 트랜잭션은 일관성 있는 DB 상태 유지해야 함(ex. DB에서 정한 무결성 제약 조건을 항상 만족)
- 격리성 (Isolation): 동시에 실행되는 트랜잭션들이 서로 영향 미치지 않도록 격리해야 함. 격리 수준은 선택 가능 (ex. 동시에 같은 데이터 수정 불가)
- 지속성 (Durability): 트랜잭션 성공적으로 종료시 결과가 항상 기록되어야 함. 중간에 시스템 문제 발생해도 DB 로그 등으로 성공한 트랜잭션 내용을 복구
- 이 중에서 격리성을 완벽히 보장하려면 트랜잭션을 거의 차례대로 실행해야 하는데, 이럴 경우 동시성 처리 성능이 나빠져서 ANSI 표준에선 트랜잭션 격리 수준을 4단계로 정의
- READ UNCOMMITTED: 커밋되지 않은 읽기 (격리 수준 가장 낮음)
- READ COMMITTED: 커밋된 읽기
- REPEATABLE READ: 반복 가능한 읽기
- SERIALIZABLE: 직렬화 가능 (격리 수준 가장 높음)
- 격리 수준 낮을수록 동시성 증가하지만 더 많은 문제가 발생하게 됨
- DIRTY READ: 커밋하지 않은 데이터 읽을 수 있음
- NON-REPEATABLE READ: 반복해서 같은 데이터 읽을 수 없음
- PHANTOM READ: 반복 조회 시 결과 집합이 달라짐
- 애플리케이션 대부분 동시성 처리가 중요하므로 보통 READ COMMITED 격리 수준을 기본으로 사용
- 중요한 비즈니스 로직 등에서 더 높은 격리 수준 필요할 경우 DB 트랜잭션이 제공하는 락 기능 사용
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PAHNTOM READ |
|---|---|---|---|
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | O | O | |
| REPEATABLE READ | O | ||
| SERIALIZABLE |
READ UNCOMMITTED
- DIRTY READ 까지 허용하는 격리 수준
- 예시
- 트랜잭션 1이 수정중인 데이터를 트랜잭션 2가 조회할 경우 DIRTY READ
- 이 때 트랜잭션 1이 롤백하면 데이터 정합성에 문제 발생할 수 있음
READ COMMITTED
- DIRTY READ 는 허용 안함
- NON-REPEATABLE READ 까지는 허용하는 격리 수준
- 예시
- 트랜잭션 1이 회원 A 조회 중 트랜잭션 2가 회원 A 수정, 커밋
- 트랜잭션 1이 회원 A 다시 조회하면 수정된 데이터 조회됨
REPEATABLE READ
- DIRTY READ, NON-REPEATABLE READ 허용 안함
- PHANTOM READ 까지는 허용하는 격리 수준
- 예시
- 트랜잭션 1이 10살 이하의 회원 조회
- 트랜잭션 2가 5살 회원 추가, 커밋
- 트랜잭션 1이 다시 10살 이하 회원 조회 시 회원 하나가 추가된 상태로 조회됨
SERIALIZABLE
- DIRTY READ, NON-REPEATABLE READ, PHANTOM READ 모두 허용 안함
- 가장 엄격한 트랜잭션 격리 수준
- 동시성 처리 성능이 급격히 떨어질 수 있음
16.1.2 낙관적 락과 비관적 락 기초
- JPA 영속성 컨텍스트(1차 캐시) 활용시 READ COMMITTED 격리 수준이어도 애플리케이션 레벨에서 REPEATABLE READ 가능함
- JPA는 DB 트랜잭션 격리 수준을 READ COMMITTED 정도로 가정하며 더 높은 격리 수준 필요할 경우 낙관적 락, 비관적 락 중 하나를 사용하면 됨
- 낙관적 락
- 트랜잭션 대부분은 충돌 발생하지 않는다고 가정하는 방법
- DB 락 대신 JPA 버전 관리 기능을 사용
- 트랜잭션 커밋 전까지는 충돌 여부 알 수 없음
- 비관적 락
- 트랜잭션 충돌 발생을 가정하고 락을 걸고 보는 방법
- DB 제공 락 기능을 사용
- 낙관적 락
- 두 번의 갱신 분실 문제 (second loast updates problem): DB 트랜잭션의 범위를 넘어서는 문제로 트랜잭션 만으로는 해결 불가능
- A와 B가 같은 데이터를 동시에 수정중인 상황
- A가 먼저 커밋한 후 이어서 B가 커밋하면 A의 수정사항은 사라지고 B 의 수정사항만 남게됨
- 해결 방법은 3가지
- 마지막 커밋만 인정하기: A의 수정 내용 무시하고 마지막 커밋인 A 의 수정 사항만 인정
- 기본적으로 사용되는 방법
- 최초 커밋만 인정하기: A가 이미 수정 끝냈으므로 B가 커밋할 때 오류 발생
- JPA 버전 관리 기능으로 구현할 수 있음
- 충돌하는 갱신 내용 병합하기: A, B 의 수정사항을 병함
- 개발자가 직접 병합 방법 제공해야 함
- 마지막 커밋만 인정하기: A의 수정 내용 무시하고 마지막 커밋인 A 의 수정 사항만 인정
16.1.3 @Version
- 엔티티에 버전 관리용 필드 추가후
@Version어노테이션 붙이면 버전 관리 기능 적용됨 @Version적용 가능 타입은 아래와 같음- Long
- Integer
- Short
- Timestamp
- 이후 엔티티 수정할 때마다 버전이 자동으로 증가하며 조회 시점 버전과 수정 시점 버전이 다르면 예외 발생
- 최초 커밋만 인정하기 적용
// 버전 관리 추가
@Entity
public class Board {
@Id
private String id;
private String title;
@Version
private Integer version;
}
...
// 버전 관리 사용
public void versionTest() {
// 트랜잭션 1 조회 title="제목A", version=1
Board board = em.find(Board.class, id);
// 트랜잭션 2에서 게시물 수정하여 title="제목C', version=2로 증가
board.setTitle("제목B"); // 트랜잭션 1 데이터 수정
save(board);
tx.commit(); // DB version=2, entity version=1이라 에외 발생
}
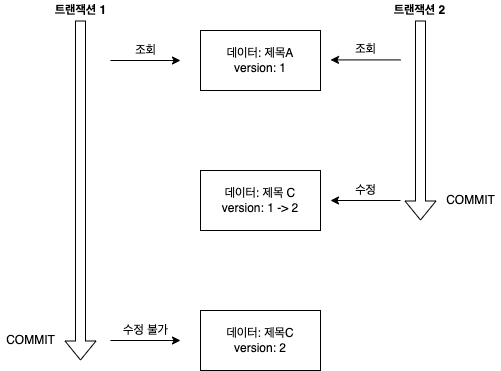
- 트랜잭션 1에서 title=제목A, version=1 인 데이터 조회
- 트랜잭션 2에서 title=제목A, version=1 인 데이터 조회
- 트랜잭션 2에서 title=제목C로 수정 후 커밋
- DB에서 title=제목C로 변경, version=2로 증가됨
- 트랜잭션 1에서 title=제목B로 수정 후 커밋
- DB의 version과 트랜잭션 1의 엔티티 버전이 달라서 예외가 발생함
버전 정보 비교 방법
UPDATE board
SET
title=?,
version=? (버전 +1 증가)
WHERE
id=?
AND version=? (버전 비교)
- 엔티티 수정, 트랜잭션 커밋 시 위와 같은 UPDATE 쿼리 실행
- DB 버전과 엔티티 버전 같으면 데이터 수정하며 버전 하나 증가시킴
- DB 버전과 엔티티 버전 다르면 WHERE 절 조건의 version 비교때문에 조회되는 값 없음
- 이미 버전이 증가한 것으로 판단해 JPA 에서 예외 발생시킴
- 버전은 엔티티 값 변경시 증가함
- 값 타입인 임베디드 타입, 값 타입 컬렉션 수정시에도 버전 증가
- 연관관계 필드는 연관관계 주인 필드를 수정할 때만 버전 증가
- 버전 관리 필드는 JPA가 직접 관리하므로 임의로 수정하면 안됨
- 벌크 연산은 제외. 벌크 연산은 버전 무시해서 증가시키려면 강제로 값 올려줘야 함
- 버전 값 강제로 증가하려면 특별한 락 옵션이 필요
16.1.4 JPA 락 사용
- 락은 다음 위치에 적용 가능
EntityManager.lock(),EntityManager.find(),EntityManager.refresh()Query.setLockMode() // TypeQuery 포함@NamedQuery
- 조회하면서 즉시 락 걸 수 있음
Board board = em.find(Board.class, id, LockModeType.OPTIMISTIC);
- 나중에 필요할 때 락 걸 수도 있음
em.lock(board, LockModeType.OPTIMISTIC);
- LockModeType 은 아래 표와 같음
| 락 모드 | 타입 | 설명 |
|---|---|---|
| 낙관적 락 | OPTIMISTIC | 낙관적 락 사용 |
| 낙관적 락 | OPTIMISTIC_FORCE_INCREMENT | 낙관적 락 + 버전 정보 강제 증가 |
| 비관적 락 | PESSIMISTIC_READ | 비관적 락, 읽기 락 사용 |
| 비관적 락 | PESSIMISTIC_WRITE | 비관적 락, 쓰기 락 사용 |
| 비관적 락 | PESSIMISTIC_FORCE_INCREMENT | 비관적 락 + 버전 정보 강제 증가 |
| 기타 | NONE | 락 걸지 않음 |
| 기타 | READ | JPA 1.0 호환 기능 OPTIMISITC 과 동일 |
| 기타 | WRITE | JPA 1.0 호환 기능 OPTIMISTIC_FORCE_INCREMENT와 동일 |
16.1.5 JPA 낙관적 락
- JPA 낙관적 락은
@Version사용 - 트랜잭션 커밋 시점에 충돌 알 수 있음
- 낙관적 락에서는 다음과 같은 예외들이 발생함
javax.persistence.OptimisticLockException: JPA 예외org.hibernate.StaleObjectStateException: 하이버네이트 예외org.springframework.orm.ObjectOptimisticLockingFailureException: 스프링 예외 추상화
- 락 옵션 없어도
@Version만 있으면 낙관적 락 적용됨- 옵션 있을 경우 더 세밀하게 제어가 가능
NONE
- 락 옵션 없이
@Version적용된 필드만으로 낙관적 락 사용 - 엔티티 수정해야 버전 체크함
- 용도
- 조회한 엔티티를 수정할 때 다른 트랜잭션에 의해 변경, 삭제 되지 않아야 함
- 조회 시점부터 수정 시점까지 보장
- 동작
- 엔티티 수정 시 버전 체크하면서 증가시킴(UPDATE 쿼리 사용)
- DB 버전 값 현재 버전 아니면 예외 발생
- 이점
- 두 번의 갱신 분실 문제 예방
OPTIMISTIC
- 이 옵션 추가시 엔티티 조회만 해도 버전을 체크함
- 용도
- 조회한 엔티티는 트랜잭션 끝날 때 까지 다른 트랜잭션에 의해 변경되지 않아야 함
- 조회 시점부터 트랜잭션 끝날 때까지 조회한 엔티티가 변경 되지 않음을 보장
- 동작
- 트랜잭션 커밋할 때 버전 정보 조회(SELECT 쿼리 사용)
- 현재 엔티티 버전과 같은지 검증해서 다르면 예외 발생
- 이점
- DIRTY READ, NON-REPEATABLE READ 방지
// OPTIMISTIC 예제
// 트랜잭션 1 조회 title="제목A", version=1
Board board = em.find(Board.class, id, LockModeType.OPTIMISTIC);
// 중간에 트랜잭션 2에서 해당 게시물 수정해서 title="제목C", version=2로 증가
// 트랜잭션 1 커밋 시점에서 버전 정보 검증, 예외 발생
// DB version=2, 엔티티 version=1
tx.commit();
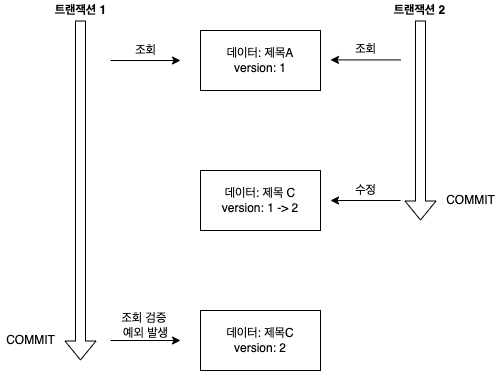
- 트랜잭션 1에서 OPTIMISTIC 락으로 데이터 조회 (title=제목A, version=1)
- 트랜잭션 2에서 해당 데이터 수정, version 증가 (title=제목C, version=2)
- 트랜잭션 1에서 트랜잭션 커밋 시 DB에 있는 버전 정보를 SELECT 쿼리로 조회해서 처음 조회한 엔티티 버전과 비교
- 버전 정보 다르면 예외 발생
OPTIMISTIC_FORCE_INCREMENT
- 낙관적 락 사용하며 버전 정보를 강제로 증가시킴
- 용도
- 논리적 단위의 엔티티 묶음 관리
- ex. 게시물과 첨부파일이 일대다, 다대일 양방향 연관관계, 첨부파일이 연관관계 주인인 경우
- 게시물 수정시 첨부파일 추가만 하면 게시물 버전은 증가하지 않음
- 게시물은 물리적으로 변경되지 않았으나 논리적으로는 변경됨
- 이럴 때 게시물 버전 강제 증가시키기 위해서 사용함
- 동작
- 엔티티 수정 안해도 트랜잭션 커밋 시 버전 정보 강제로 증가(UPDATE 쿼리 사용)
- DB 버전과 엔티티 버전 다르면 예외 발생
- 추가로 엔티티 수정하면 수정 시 버전 UPDATE 쿼리 발생해서 총 2 번의 버전 증가 나타날 수 있음
- 이점
- 논리적 단위의 엔티티 묶음 버전 관리할 수 있음
// OPTIMISTIC_FORCE_INCREMENT
// 트랜잭션 1 조회 title="제목A", version=1
Board board = em.find(Board.class, id, LockModeType.OPTIMISTIC_FORCE_INCREMENT);
// 트랜잭션 1 커밋 시 버전 강제 증가
tx.commit();
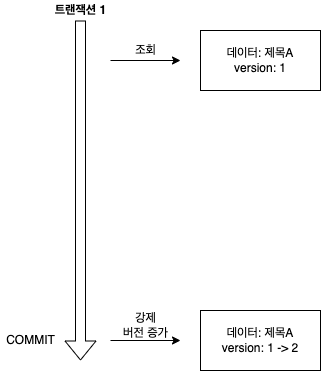
16.1.6 JPA 비관적 락
- DB 트랜잭션 락 메커니즘에 의존하는 방법
- 주로 쿼리에
SELECT FOR UPDATE구문 사용하며 시작, 버전 정보는 안씀 - 주로 PESSIMISTIC_WRITE 모드 사용함
- 특징은 다음과 같음
- 엔티티가 아닌 스칼라 타입 조회 시에도 사용 가능
- 데이터 수정 즉시 트랜잭션 충돌 감지 가능
- 발생하는 예외는 다음과 같음
javax.persistence.PessimisticLockException: JPA 예외org.springframework.dao.PessimisticLockingFailureException: 스프링 예외 추상화
PESSIMISTIC_WRITE
- 일반적으로 말하는 비관적 락 옵션
- 용도
- DB에 쓰기 락 검
- 동작
- DB
SELECT FOR UPDATE사용
- DB
- 이점
- NON-REPEATABLE READ 방지
- 락이 걸린 row는 다른 트랜잭션이 수정 불가
PESSIMISTIC_READ
- 데이터 반복 읽기만 하고 수정 안하는 용도로 락 걸때 사용
- 대부분 DB에서 방언에 의해 PESSIMISTIC_WRITE 로 동작
- MySQL: lock in share mode
- PostgreSQL: for share
PESSIMISTIC_FORCE_INCREMENT
- 버전 정보를 사용하는 유일한 비관적 락
- 버전 정보를 강제로 증가시킴
- 하이버네이트는 nowait 지원 DB에 한해서 for update nowait 옵션을 적용
- 오라클: for update nowait
- PostgreSQL: for update nowait
- nowait 지원 안하면 for update 사용
16.1.7 비관적 락과 타임아웃
- 비관적 락 사용하면 락 획득시까지 트랜잭션이 대기하는데 이 때 타임아웃 시간을 설정할 수 있음
- 지정한 타임아웃 시간 지나면
javax.persistence.LockTimeoutException예외 발생 - DB 특성 따라 동작 안할 수도 있으므로 주의
// 타임아웃 설정 예제
Map<String, Object> properties = new HashMap<String, Object>();
// timeout 10초 설정
properties.put("javax.persistence.lock.timeout", 10000); // ms 단위로 설정
// 10초 안에 락 획득 못하면 예외 발생함
Board board = em.find(Board.class, "boardId", LockModeType.PESSIMISTIC_WRITE, properties);
16.2 2차 캐시
16.2.1 1차 캐시와 2차 캐시
- 네트워크로 DB 접근 시간 비용은 애플리케이션 서버에서 내부 메모리 접근 시간 비용에 비해 수만, 수십배 이상 비쌈
- 따라서 조회한 데이터 메모리 캐시해 DB 접근 횟수 줄이면 성능 개선 가능
- 영속성 컨텍스트 내부 1차 캐시는 트랜잭션 시작 -> 종료 까지만 유효함
- OSIV 사용해도 클라이언트 요청 끝날 때 까지만 유효해서 전체적으로 DB 접근 횟수를 많이 줄일 수는 없음
- ∴ 대부분의 JPA 구현체들에서 애플리케이션 범위의 캐시를 지원 => 공유 캐시(2차 캐시)
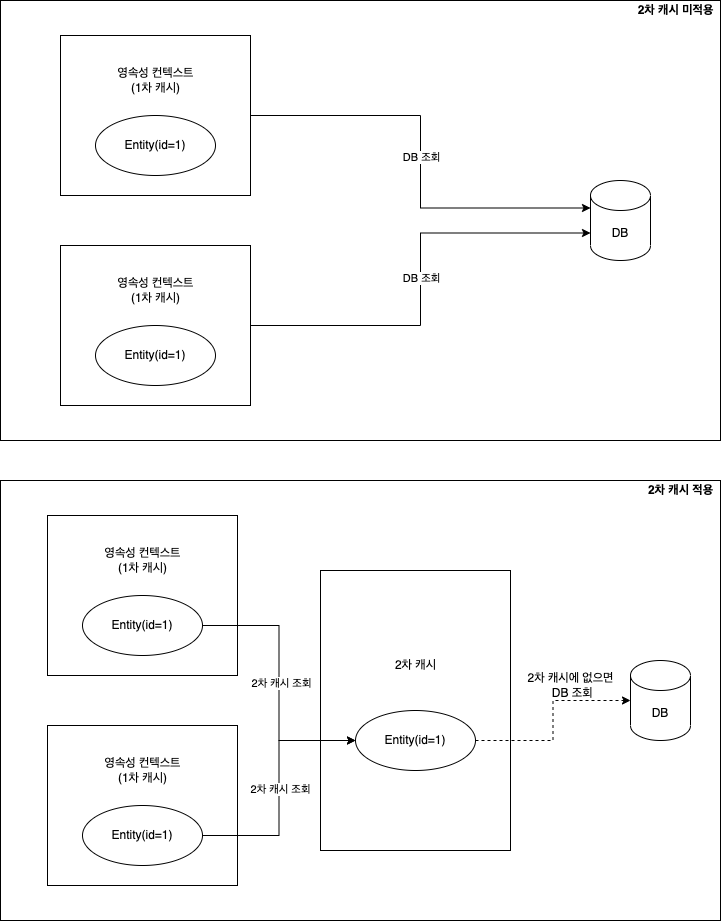
1차 캐시
- 영속성 컨텍스트 내부에 존재하며 엔티티 매니저로 조회, 변경하는 모든 엔티티가 저장됨
- 트랜잭션 커밋하거나 플러시 호출시 1차 캐시에 있는 엔티티의 변경 내역이 DB에 동기화 됨
- 같은 엔티티가 있으면 해당 엔티티 그대로 반환 => 객체 동일성 보장
- 기본적으로 영속성 컨텍스트 범위의 캐시
- 컨테이너 환경: 트랜잭션 시작시 영속성 컨텍스트 생성, 트랜잭션 종료시 영속성 컨텍스트도 종료 => 트랜잭션 범위의 캐시
- OSIV 적용: 요청 들어올 때 영속성 컨텍스트 생성, 요청 종료시 영속성 컨텍스트도 종료 => 요청 범위의 캐시
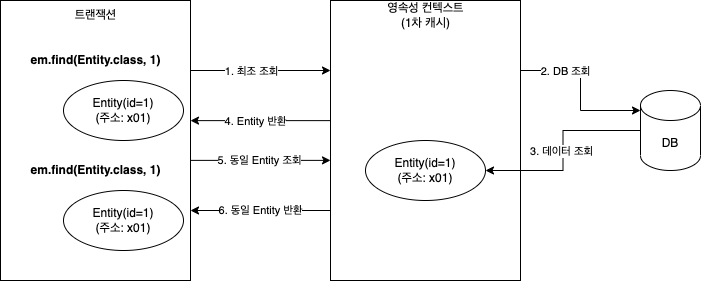
- 최초 조회시 1차 캐시에 엔티티 없음
- DB에서 엔티티 조회
- 1차 캐시에 보관
- 1차 캐시 보관 결과 반환
- 같은 엔티티 조회
- DB 조회 없이 앞서 1차 캐시에 보관한 엔티티 반환
2차 캐시
- 애플리케이션에서 공유하는 캐시
- JPA에서는 공유 캐시(shared cache), 일반적으로는 2차 캐시라고 부름(second level cache. L2 cache)
- 애플리케이션 종료시 까지 유지되며 분산 캐시, 클러스터링 환경의 캐시는 애플리케이션보다 더 오래 유지될 수 있음
- 2차 캐시 적용 시 DB 조회 전에 2차 캐시부터 찾음
- 동시성 극대화를 위해 캐시한 객체 복사본을 만들어 반환함
- 원본 반환 시 여러 곳에서 같은 객체 동시에 수정할 수 있는 문제 생김
- 락 거는 것 보다 복사본 만드는게 비용 저렴
- 영속성 유닛 범위의 캐시
- DB 기본 키를 기준으로 캐시하지만 영속성 컨텍스트 다르면 객체 동일성 보장 안함
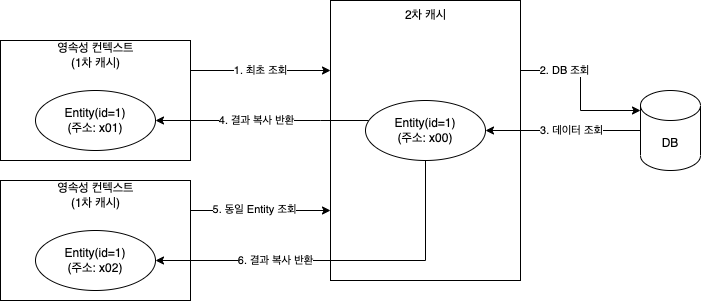
- 영속성 컨텍스트가 엔티티 필요하면 2차 캐시 조회
- 2차 캐시에 엔티티 없으면 DB 조회
- 결과를 2차 캐시에 보관
- 2차 캐시는 자신이 보관하고 있던 엔티티 복사해서 반환
- 같은 엔티티 조회
- 2차 캐시에 저장되어 있는 엔티티 복사본 만들어서 반환
16.2.2 JPA 2차 캐시 기능
캐시 모드 설정
- 2차 캐시 사용하려면 엔티티에
javax.persistence.Cacheable어노테이션 사용@Cacheable의 기본값은 true
- 또한 persistence.xml 에 shared-cache-mode 설정해서 애플리케이션 전체(==영속성 유닛 단위) 캐시를 어떻게 적용할 지 옵션 설정해야 함
- 스프링은 entityManagerFacotry 빈 프로퍼티에 sharedCacheMode 설정
- 캐시 모드는 아래 표 참조
| 캐시 모드 | 설명 |
|---|---|
| ALL | 모든 엔티티를 캐시 |
| NONE | 캐시 사용 안함 |
| ENABLE_SELECTIVE | Cacheable(true)로 설정된 엔티티만 캐시 적용 |
| DISABLE_SELECTIVE | Cacheable(false)로 설정된 엔티티만 빼고 캐시 적용 |
| UNSPECIFIED | JPA 구현체가 정의한 설정 따름 |
// 엔티티에 캐시 사용 옵션 적용
@Cacheable
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
...
}
<!-- persistence.xml 캐시 모드 설정 -->
<persistence-unit name="test">
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
</persistence-unit>
<!-- 스프링 xml 캐시 모드 설정 -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="sharedCacheMode" value="ENABLE_SELECTIVE"/>
...
캐시 조회, 저장 방식 설정
- 캐시 무시하고 DB 직접 조회 또는 캐시 갱신하려면 캐시 조회 모드, 캐시 보관 모드 사용
- 캐시 조회 모드
- 프로퍼티 이름:
javax.persistence.cache.retrieveMode - 설정 옵션:
javax.persistence.CacheRetrieveMode- USE: 캐시에서 조회. default 값
- BYPASS: 캐시 무시하고 DB 직접 접근
- 프로퍼티 이름:
- 캐시 보관 모드
- 프로퍼티 이름:
javax.persistence.cache.storeMode - 설정 옵션:
javax.persistnce.CacheStoreMode- USE: 조회한 데이터 캐시에 저장. 이미 있으면 최신 상태로 갱신 안함. 트랜잭션 커밋 시 등록 수정한 엔티티도 캐시에 저장. 기본값
- BYPASS: 캐시 저장 안함
- REFRESH: USE 전략 + DB 에서 조회한 엔티티를 최신 상태로 갱신
- 프로퍼티 이름:
- 캐시 모드는
Entity.setProperty()로 엔티티 매니저 단위로 설정 가능 - 좀더 세밀하게 하려면
EntityManager.find(),EntityManager.refresh()에 설정 Query.setHint() // TypeQuery 포함에 설정할 수도 있음
// 엔티티 매니저 범위 예제
em.setProperty("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
em.setPRoperty("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS);
...
// find() 에 적용 예제
Map<String, Object> param = new HashMap<String, Object>() {
{
put("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
put("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS);
}
};
em.find(TestEntity.class, id, param);
...
// setHint() 에 적용 예제
em.createQuery("SELECT e FROM TestEntity e WHERE e.id = :id", TestEntity.class)
.setParameter("id", id)
.setHint("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS)
.setHint("javax.persistence.cache.storeMode", CacheStoreMode.BYPASS)
.getSingleResult();
JPA 캐시 관리 API
- JPA는 캐시 관리를 위해
javax.persistence.cache인터페이스 제공- EntityManagerFactory 에서 구해서 사용할 수 있음
// Cache 사용 예제
Cache cache = emf.getCache();
boolean contains = cache.contains(TestEntity.class, TestEntity.getId());
System.out.println("contains = " + contains);
// Cache 인터페이스
public interface Cache {
// 해당 엔티티 캐시에 있는지 여부 확인
public boolean contains(Class cls, Object primaryKey);
// 해당 엔티티중 특정 식별자 가진 엔티티를 캐시에서 제거
public void evict(Class cls, Object primaryKey);
// 해당 엔티티 전체를 캐시에서 제거
public void evict(Class cls);
// 모든 캐시 데이터 제거
public void evictAll();
// JPA Cache 구현체 조회
public <T> T unwrap(Class<T> cls);
}
16.2.3 하이버네이트와 EHCACHE 적용
- 하이버네이트가 지원하는 캐시는 크게 3가지
- 엔티티 캐시
- 엔티티 단위로 캐시
- 식별자로 엔티티 조회 또는 컬렉션이 아닌 연관된 엔티티 로딩 시 사용
- JPA 표준
- 컬렉션 캐시
- 엔티티와 연관된 컬렉션을 캐시
- 컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시
- 하이버네이트 기능
- 쿼리 캐시
- 쿼리와 파라미터 정보를 키로 사용해서 캐시
- 결과가 엔티티면 식별자 값만 캐시
- 하이버네이트 기능
- 엔티티 캐시
환경설정
- 하이버네이트에서 EHCACHE 사용하기 위해 pom.xml에 hibernate-ehcache 라이브러리 추가
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
</dependency>
- EHCACHE 용 설정파일 ehcache.xml 생성
- 보관할 캐시 양, 보관 기간 등 정책 설정용 파일
<!-- src/main/resources/ehcache.xml -->
<ehcache>
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSecons="1200"
timeToLiveSeconds="1200"
diskExpiryThreadIntervalSeconds="1200"
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>
- 하이버네이트에 캐시 사용정보 설정하기 위해 persistence.xml에 캐시 정보 추가
hibernate.cache.use_second_level_cache: 2차 캐시 활성화. 엔티티 캐시 & 컬렉션 캐시 사용 가능hibernate.cache.use_query_cache: 쿼리 캐시 활성화hibernate.cache.region.factory_class: 2차 캐시 처리할 클래스 지정hibernate.generate_statistics: true 설정 시 통계 정보 출력해줘서 캐시 적용 여부 확인 가능. 성능 악영향 주므로 개발에만 적용 추천
<!-- persistence.xml -->
<persistence-unit name="test">
<sahred-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
<properties>
<property name="hibernate.cache.user_second_level_cache" value="true"/>
<property name="hibernate.cache.use_query_cache" value="true"/>
<property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.ehcache.EhCacheRegionFactory">
<property name="hibernate.generate_statistics" value="true"/>
</properties>
...
</persistence-unit>
엔티티 캐시와 컬렉션 캐시
@Cacheable // 엔티티에 캐시 적용 설정
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE) // 하이버네이트 전용. 좀 더 세밀한 캐시 설정할 때 사용
@Entity
public class ParentMember {
@Id
@GeneratedValue
private Long id;
private String name;
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE) // 하이버네이트 전용. 여기처럼 컬렉션 캐시 적용할 때도 사용
@OneToMany(mappedBy = "parentMember", cascade = CascadeType.ALL)
private List<ChildMember> childMembers = new ArrayList<ChildMember>();
...
}
- 위 예제의 경우
ParentMember는 엔티티 캐시,ParentMember.childMembers는 컬렉션 캐시가 적용됨
@Cache
- 앞서 얘기한 것 처럼
org.hibernate.annotations.Cache어노테이션으로 세밀한 캐시 설정이 가능
| 속성 | 설명 |
|---|---|
| usage | CacheConcurrencyStrategy 사용해서 캐시 동시성 전략 설정 |
| region | 캐시 지역 설정 (Cache Region) |
| include | 연관 객체를 캐시에 포함할지 선택 (all, non-lazy) default는 all |
- usage 속성 설정에 사용되는
org.hibernate.annotations.CacheConcurrencyStrategy속성은 다음과 같음
| 속성 | 설명 |
|---|---|
| NONE | 캐시 설정 안함 |
| READ_ONLY | 일기 전용 설정 등록, 삭제는 가능, 수정 불가능 읽기 전용 불변 객체는 수정되지 않으므로 이 설정 해두면 2차 캐시 조회시 원본 객체 반환 |
| NONSTRICT_READ_WRITE | 엄격하지 않은 읽고 쓰기 전략 동시에 같은 엔티티 수정시 데이터 일관성 깨질 수 있음 EHCACHE는 데이터 수정하면 캐시 데이터 무효화함 |
| READ_WRITE | 읽기 쓰기 가능하고 READ_COMMITED 정도 격리 수준 보장 EHCACHE는 데이터 수정하면 캐시 데이터도 같이 수정함 |
| TRANSACTIONAL | 컨테이너 관리 환경에서 사용 가능 설정에 따라 REPEATABLE_READ 정도 경리 수준 보장 가능 |
캐시 영역
- 엔티티 캐시 영역은 기본값으로 [패키지명 + 클래스명] 사용
- 위 예제의
ParentMember엔티티 캐시의 경우jpabook.jpashop.domain.test.cache.ParentMember에 저장
- 위 예제의
- 컬렉션 캐시 영역은 [엔티티 캐시 영역 이름 + 캐시한 컬렉션의 필드명] 사용
- 위 예제의
ParentMember.childMembers컬렉션 캐시의 경우jpabook.jpashop.domain.test.cache.ParentMember.childMembers에 저장
- 위 예제의
- 필요시
@Cache어노테이션의 region 속성으로 직접 지정할 수도 있음 - 캐시 영역 접두사 설정은 persistence.xml에
hibernate.cache.region_prefix설정해주면 됨 - 캐시 영역이 지정되어있으므로 아래 예제와 같이 ehcahce.xml에서 영역별 세부 설정이 가능
<!-- ehchache.xml -->
<!-- ParentMember를 600초마다 캐시에서 제거하는 설정 예제 -->
<ehcache>
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSecons="1200"
timeToLiveSeconds="1200"
diskExpiryThreadIntervalSeconds="1200"
memoryStoreEvictionPolicy="LRU"
/>
<cache
name="jpabook.jpashop.domain.test.cache.ParentMember"
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="600"
timeToLiveSeconds="600"
overflowToDisk="false"
/>
</ehcache>
쿼리 캐시
- 쿼리와 파라미터 정보를 키로 사용해서 쿼리 결과를 캐시하는 방법
- 적용을 위해서는
hibernate.cache.use_query_cache옵션 true 설정해야 함 - 또한 쿼리 캐시 적용할 쿼리마다 힌트에
org.hibernate.cacheabletrue 로 설정
// 쿼리 캐시 적용
em.createQuery("SELECT i FROM Item i", Item.class)
.setHint("org.hibernate.cacheable", true)
.getResultList();
// NamedQuery에 쿼리 캐시 적용
@Entity
@namedQuery(
hints = @QueryHint(name = "org.hibernate.cacheable", value = "true"),
name = "Member.findByUsername"
query = "SELECT m.address FROM Member m WHERE m.name = :username"
)
public class Member {
...
}
쿼리 캐시 영역
hibernate.cache.use_query_cache옵션 true 설정해서 쿼리 캐시 활성화 시 다음 두 캐시 영역 추가됨- org.hibernate.cache.internal.StandardQueryCache
- 쿼리 캐시 저장하는 영역
- 쿼리, 쿼리 결과 집합, 쿼리 실행 시점의 타임 스탬프 보관
- org.hibernate.cache.spi.UpdateTimestampsCache
- 쿼리 캐시 유효성 여부 체크를 위해 쿼리 대상 테이블의 가장 최근 변경(등록, 수정, 삭제) 시간 저장하는 영역
- 테이블 명과 해당 테이블이 최근 변경된 시점의 타임스탬프 보관
- 이 영역 만료되면 모든 쿼리 캐시 무효화 되므로 만료되지 않도록 설정 필요
- ehcache.xml에서
org.hibernate.cache.spi.UpdateTimestampsCache영역에 대해eternal="true"옵션 주면 됨
- ehcache.xml에서
- org.hibernate.cache.internal.StandardQueryCache
- 쿼리 캐시 적용 후 엔티티 변경하면
org.hibernate.cache.spi.UpdateTimestampsCache영역에 해당 엔티티가 매핑한 테이블 이름으로 타임스탬프 갱신 - 쿼리 캐시는 캐시한 데이터 집합을 최신으로 유지하기 위해 쿼리 캐시 실행 시점과 쿼리 캐시가 사용하는 테이블들의 가장 최근 변경 시점을 비교
- 만약 쿼리 캐시 적용 후 테이블에 조금이라도 변경 있으면 DB에서 다시 데이터 읽어와서 쿼리 결과 캐시함
- 따라서 변경이 잦은 테이블에 쿼리 캐시 사용하면 성능 저하될 수 있으므로 수정 적은 테이블에 적용하는게 좋음
쿼리 캐시와 컬렉션 캐시의주의점
- 엔티티 캐시를 사용해서 엔티티 캐시하면 엔티티 정보 모두 캐시
- 쿼리 캐시와 컬랙션 캐시는 결과 집합의 실별자 값만 캐시
- 쿼리 캐시, 컬렉션 캐시 조회하면 실제 엔티티가 아닌 식별자 값만 들어있음
- 이 식별자 값으로 다시 엔티티 캐시에서 조회해서 실제 엔티티 찾는 것
- 따라서 쿼리 캐시나 컬렉션 캐시만 쓰고 엔티티 캐시 안쓰면 성능 문제 발생할 수 있음
- 예시
- 쿼리 캐시가 적용되어있는
SELECT m FROM Member m쿼리 실행. 결과 집합은 100건 - 100건에 대해 한 건씩 엔티티 캐시 영역에서 식별자 값으로 조회
- 엔티티 캐시 적용 안되어 있으면 다시 한 건씩 DB에서 조회
- 결과적으로 DB에서 100번 쿼리 실행됨
- 쿼리 캐시가 적용되어있는
- 이런 문제 방지하기 위해서는 쿼리 캐시, 컬렉션 캐시 사용할 때 결과 대상 엔티티에 꼭 엔티티 캐시 적용해야 함
- 예시
Subscribe via RSS
{kind=link}